Presentation
Overcoming the Gap between Compute and Memory Bandwidth in Modern GPUs
DescriptionThe imbalance between compute and memory bandwidth has been a long-standing issue. Despite efforts to address it, the gap between them is still widening. This has led to the categorization of many applications as memory-bound kernels.
This dissertation centers on memory-bound kernels, with a particular emphasis on Graphics Processing Units (GPUs), given their rising prevalence in High-Performance Computing (HPC) systems.
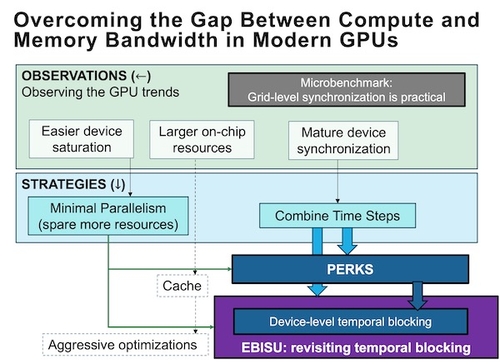
In this dissertation, we initially focus on the evolution trend of GPU development in the last decades. Examples include cooperative groups (i.e., device-wide barriers), asynchronous copy of shared memory (i.e., hardware prefetching), low(er) latency of operations, and larger volume of on-chip resources (register files and L1 cache).
This dissertation seeks to utilize the latest GPU features to optimize memory-bound kernels. Specifically, we propose extending the kernel's lifetime across the time steps and taking advantage of the large volume of on-chip resources (i.e., register files and scratchpad memory) in reducing or eliminating traffic to the device memory. Furthermore, we champion a minimum level of parallelism to maximize the available on-chip resources.
Based on the strategies, we propose a general execution model for running memory-bound iterative GPU kernels: PERsistent KernelS (PERKS) and a novel temporal blocking method, EBISU. Evaluations have shown outstanding performance in the latest GPU architectures compared with counterpart state-of-the-art implementations.
This dissertation centers on memory-bound kernels, with a particular emphasis on Graphics Processing Units (GPUs), given their rising prevalence in High-Performance Computing (HPC) systems.
In this dissertation, we initially focus on the evolution trend of GPU development in the last decades. Examples include cooperative groups (i.e., device-wide barriers), asynchronous copy of shared memory (i.e., hardware prefetching), low(er) latency of operations, and larger volume of on-chip resources (register files and L1 cache).
This dissertation seeks to utilize the latest GPU features to optimize memory-bound kernels. Specifically, we propose extending the kernel's lifetime across the time steps and taking advantage of the large volume of on-chip resources (i.e., register files and scratchpad memory) in reducing or eliminating traffic to the device memory. Furthermore, we champion a minimum level of parallelism to maximize the available on-chip resources.
Based on the strategies, we propose a general execution model for running memory-bound iterative GPU kernels: PERsistent KernelS (PERKS) and a novel temporal blocking method, EBISU. Evaluations have shown outstanding performance in the latest GPU architectures compared with counterpart state-of-the-art implementations.