Posters Gallery
Tuesday, 14 November 2023 10am-5pm E Concourse
Hide Details

I/O Efficient Machine Learning
DescriptionMy research focuses on systems optimizations for machine learning, specifically on I/O efficient model storage and retrieval.
The first part of my work focuses on efficient inference serving of tree ensemble models. Tree structures are inherently not cache friendly and their traversal incurs random I/Os. We developed two systems - Blockset (Block Aligned Serialized Trees) and T-REX (Tree Rectangles).
Blockset improves inference latency in the scenario where the model doesn’t fit in memory. It introduces the concept of selective access for tree ensembles in which only the parts of the model needed for inference are deserialized and loaded into memory. It uses principles from external memory algorithms to rearrange tree nodes in a block aligned format to minimize the number of I/Os needed for inference. T-REX optimizes inference latency for both in-memory inference as well as inference when the model doesn’t fit in memory. T-REX reformulates decision tree traversal as hyperrectangle enclosure queries using the fact that decision trees partition the space into convex hyperrectangles. The test points are then queried for enclosure inside the hyperrectangles. In doing random I/O is traded for additional computation.
The second part of my work focuses on efficient deep learning model storage. We implemented a deep learning model repository that requires fine-grained access to individual tensors in models. This is useful in applications such as transfer learning, where individual tensors in layers are transferred from one model to another. We’re currently working on caching and prefetching popular tensors based on application level hints.
The first part of my work focuses on efficient inference serving of tree ensemble models. Tree structures are inherently not cache friendly and their traversal incurs random I/Os. We developed two systems - Blockset (Block Aligned Serialized Trees) and T-REX (Tree Rectangles).
Blockset improves inference latency in the scenario where the model doesn’t fit in memory. It introduces the concept of selective access for tree ensembles in which only the parts of the model needed for inference are deserialized and loaded into memory. It uses principles from external memory algorithms to rearrange tree nodes in a block aligned format to minimize the number of I/Os needed for inference. T-REX optimizes inference latency for both in-memory inference as well as inference when the model doesn’t fit in memory. T-REX reformulates decision tree traversal as hyperrectangle enclosure queries using the fact that decision trees partition the space into convex hyperrectangles. The test points are then queried for enclosure inside the hyperrectangles. In doing random I/O is traded for additional computation.
The second part of my work focuses on efficient deep learning model storage. We implemented a deep learning model repository that requires fine-grained access to individual tensors in models. This is useful in applications such as transfer learning, where individual tensors in layers are transferred from one model to another. We’re currently working on caching and prefetching popular tensors based on application level hints.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Artificial Intelligence/Machine Learning
I/O and File Systems
TP
XO/EX
Archive
view
Hide Details
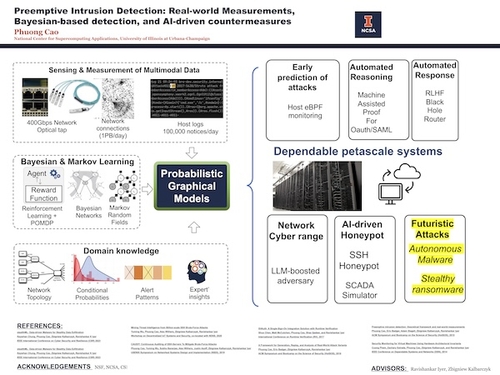
Preemptive Intrusion Detection: Real-World Measurements, Bayesian-Based Detection, and AI-Driven Countermeasures
DescriptionThe problem of preempting attacks before damages remains the top security priority. The gap between alerts and early detection remains wide open because noisy attack attempts and unreliable alerts mask real attacks from humans. This dissertation brings together: 1) attack patterns mining driven by real security incidents, 2) probabilistic graphical models linking patterns with runtime alerts, and 3) an in vivo testbed which embeds a honeypot in a live Science DMZ network for realistic assessment. Traditional techniques that seek specific attack signatures or anomalies are ineffective because defenders only see a partial view of ongoing attacks while having to wrestle with unreliable alerts and heavy background noise of attack attempts. In contrast, our principle objective is to reinforce scant, incomplete evidence of potential attacks with the ground truth of past security incidents. We evaluated our system, Cyborg's, accuracy, and performance in three experiments at the National Center for Supercomputing Applications at the University of Illinois. Our deployment stops 8 out of 10 replayed attacks before system integrity violation and all ten before data exfiltration. In addition, we discovered and stopped a family of ransomware attacks before the data breach. During the period of deployment, this thesis resulted in a honeypot that collected 15 billion attack attempts (the world's largest publicly analyzed dataset) for analytics. In the future, we are looking at integrating AI techniques such as large language models to build intelligent honeypot systems that are indistinguishable from real systems to collect attack intelligence and educate the security operator.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Artificial Intelligence/Machine Learning
Security
TP
XO/EX
Archive
view
Hide Details

High Performance Serverless for HPC and Clouds
DescriptionFunction-as-a-Service (FaaS) computing brought a fundamental shift in resource management. It allowed for new and better solutions to the problem of low resource utilization, an issue that has been known in data centers for decades. The problem persists as the frequently changing resource availability cannot be addressed entirely with techniques such as persistent cloud allocations and batch jobs. The elastic fine-grained tasking and largely unconstrained scheduling of FaaS create new opportunities. Still, modern serverless platforms struggle to achieve the high performance needed for the most demanding and latency-critical workloads. Furthermore, many applications cannot be “FaaSified” without non-negligible loss in performance, and the short and stateless functions employed in FaaS must be easy to program, debug, and optimize. By solving the fundamental performance challenges of FaaS, we can build a fast and efficient programming model that brings innovative cloud techniques into HPC data centers, allowing users to benefit from pay-as-you-go billing and helping operators to decrease running costs and their environmental impact. My PhD research attempts to bridge the gap between high-performance programming and modern FaaS computing frameworks. I have been working on tailored solutions for different levels of the FaaS computing stack: from computing and network devices to high-level optimizations and efficient system designs.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Cloud Computing
TP
XO/EX
Archive
view
Hide Details

Corralling the Computing Continuum: Mobilizing Modern Distributed Resources for Machine Learning and Accessible Computing
DescriptionTo achieve the resource agnostic flexibility of compute described by the computing continuum, we combined our work in workload profiling and cost estimation with task provisioning to present DELTA–a framework for serverless workload placement across a computing ecosystem. To address the dynamic availability of modern computing resources as well as the multiple costs involved in computing, we presented extensions of our framework as DELTA+ which demonstrated the ability for resource provisioning and multidimensional compute costs.
To bring this idea of resource abstraction via serverless into the rapidly growing field of federated learning, we developed and released FLoX: Federated Learning on funcX. This framework was built from the ground up around a serverless computing paradigm with experimentation and usability in mind. Extending the lessons learned from DELTA around self-adaptive systems, we began exploring the potential of automating tradeoffs found in FLoX and federated learning in general.
Looking ahead, we are developing FLoX into a much more robust framework to enable the use of a wide range of computing resources while abstracting away the difficulties of configuring and optimizing a federated learning experiment. Additionally, we are actively working on a re-release of DELTA with all extensions combined into one framework with updated cost and execution time predictors and complete resource provisioning ability. Finally, we are designing an integration between FLoX and DELTA that will enable serverless-based FL to automatically place each component of an FL flow and move data as necessary to best use the available resources.
To bring this idea of resource abstraction via serverless into the rapidly growing field of federated learning, we developed and released FLoX: Federated Learning on funcX. This framework was built from the ground up around a serverless computing paradigm with experimentation and usability in mind. Extending the lessons learned from DELTA around self-adaptive systems, we began exploring the potential of automating tradeoffs found in FLoX and federated learning in general.
Looking ahead, we are developing FLoX into a much more robust framework to enable the use of a wide range of computing resources while abstracting away the difficulties of configuring and optimizing a federated learning experiment. Additionally, we are actively working on a re-release of DELTA with all extensions combined into one framework with updated cost and execution time predictors and complete resource provisioning ability. Finally, we are designing an integration between FLoX and DELTA that will enable serverless-based FL to automatically place each component of an FL flow and move data as necessary to best use the available resources.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Cloud Computing
Distributed Computing
TP
XO/EX
Archive
view
Hide Details
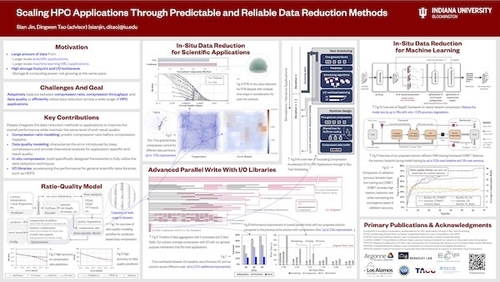
Scaling HPC Applications through Predictable and Reliable Data Reduction Methods
DescriptionFor scientists and engineers, large-scale computer systems are one of the most powerful tools to solve complex high-performance computing (HPC) and Deep Learning (DL) problems. With the ever-increasing computing power such as the new generation of exascale (one exaflop or a billion billion calculations per second) supercomputers, the gap between computing power and limited storage capacity and I/O bandwidth has become a major challenge for scientists and engineers. Large-scale scientific simulations on parallel computers can generate extremely large amounts of data that are highly compute and storage intensive. This study will introduce data reduction techniques as a promising solution to significantly reduce the data sizes while maintaining high data fidelity for post-analyses in HPC applications. This study can be categorized into mainly four scenarios: (1) A ratio-quality model that makes lossy compression predictable; (2) advanced parallel write solution with async-I/O; (3) in-situ data reduction for scientific applications; and (4) in-situ data reduction for large-scale machine learning.

Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Data Compression
I/O and File Systems
TP
XO/EX
Archive
view
Hide Details
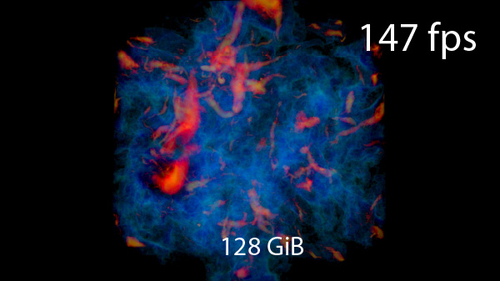
Interactive In-Situ Visualization of Large Distributed Volume Data
DescriptionLarge distributed volume data are routinely produced in numerical simulations and experiments. In-situ visualization, the visualization of simulation or experiment data as it is generated, enables simulation steering and experiment control, which helps scientists gain an intuitive understanding of the studied phenomena. Such data exploration requires interactive visualization with smooth viewpoint changes and zooming to convey depth perception and spatial understanding. As data sizes increase, this becomes increasingly challenging.
This thesis presents an end-to-end solution for interactive in-situ visualization on distributed computers based on novel extensions to the Volumetric Depth Image (VDI) representation. VDIs are view-dependent, compact representations of volume data that can be rendered faster than the original data.
We propose the first algorithm to generate VDIs on distributed 3D data, using sort-last parallel compositing to scale to large data sizes. Scalability is achieved by a novel compact in-memory representation of VDIs that exploits sparsity and optimizes performance. We also propose a low-latency architecture for sharing data and hardware resources with a running simulation. The resulting VDI is streamed for remote interactive visualization.
We provide a novel raycasting algorithm for rendering streamed VDIs, significantly outperforming existing solutions. We exploit properties of perspective projection to minimize calculations in the GPU kernel and leverage spatial smoothness in the data to minimize memory accesses.
The quality and performance of the approach are evaluated on multiple datasets, showing that the approach outperforms state-of-the-art techniques for visualizing large distributed volume data. The contributions are implemented as extensions to established open-source tools.
This thesis presents an end-to-end solution for interactive in-situ visualization on distributed computers based on novel extensions to the Volumetric Depth Image (VDI) representation. VDIs are view-dependent, compact representations of volume data that can be rendered faster than the original data.
We propose the first algorithm to generate VDIs on distributed 3D data, using sort-last parallel compositing to scale to large data sizes. Scalability is achieved by a novel compact in-memory representation of VDIs that exploits sparsity and optimizes performance. We also propose a low-latency architecture for sharing data and hardware resources with a running simulation. The resulting VDI is streamed for remote interactive visualization.
We provide a novel raycasting algorithm for rendering streamed VDIs, significantly outperforming existing solutions. We exploit properties of perspective projection to minimize calculations in the GPU kernel and leverage spatial smoothness in the data to minimize memory accesses.
The quality and performance of the approach are evaluated on multiple datasets, showing that the approach outperforms state-of-the-art techniques for visualizing large distributed volume data. The contributions are implemented as extensions to established open-source tools.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Data Analysis, Visualization, and Storage
TP
XO/EX
Archive
view
Hide Details
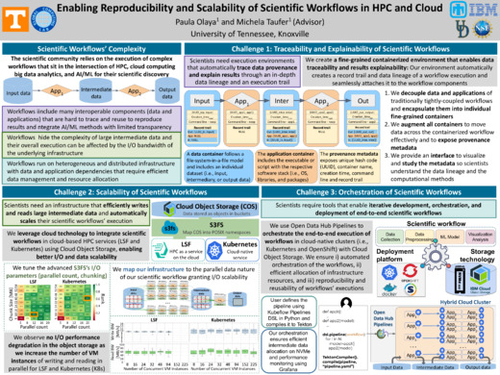
Enabling Reproducibility and Scalability of Scientific Workflows in HPC and Cloud
DescriptionScientific communities across fields like earth science, biology, and materials science increasingly run complex workflows for their scientific discovery. We work closely with these communities to leverage high-performance computing (HPC), big data analytics, and artificial intelligence/machine learning (AI/ML) to increase and accelerate their workflows’ productivity. Our work addresses the new challenges brought about by this optimization process.
We identify three main challenges in these workflows: i) they integrate AI/ML methods with limited transparency and include many interoperable components (data and applications) that are hard to trace and reuse to reproduce results; ii) they hide the complexity of large intermediate data and their overall execution can be affected by the I/O bandwidth of the underlying infrastructure; and iii) they run on heterogeneous and distributed infrastructure with data and application dependencies that require efficient data management and resource allocation.
To address these challenges, we provide solutions that leverage the convergence between high-performance and cloud computing. First, we design and develop fine-grained containerized environments that enable data traceability and results explainability by automatically annotating and seamlessly attaching provenance information. Second, since the workflows are already containerized, we integrate them in HPC and native-cloud infrastructure and tune the storage technology to enable better I/O and data scalability. Finally, we orchestrate the end-to-end execution of workflows, ensuring efficient allocation of infrastructure resources and intermediate data management, and supporting reproducibility and reusability of workflows’ executions.
We identify three main challenges in these workflows: i) they integrate AI/ML methods with limited transparency and include many interoperable components (data and applications) that are hard to trace and reuse to reproduce results; ii) they hide the complexity of large intermediate data and their overall execution can be affected by the I/O bandwidth of the underlying infrastructure; and iii) they run on heterogeneous and distributed infrastructure with data and application dependencies that require efficient data management and resource allocation.
To address these challenges, we provide solutions that leverage the convergence between high-performance and cloud computing. First, we design and develop fine-grained containerized environments that enable data traceability and results explainability by automatically annotating and seamlessly attaching provenance information. Second, since the workflows are already containerized, we integrate them in HPC and native-cloud infrastructure and tune the storage technology to enable better I/O and data scalability. Finally, we orchestrate the end-to-end execution of workflows, ensuring efficient allocation of infrastructure resources and intermediate data management, and supporting reproducibility and reusability of workflows’ executions.

Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Reproducibility
TP
XO/EX
Archive
view
Hide Details

Modernizing Simulation Software for the Exascale Era
DescriptionModern HPC hardware is becoming increasingly heterogeneous and diverse in the exascale era. The diversity of hardware and software stacks adds additional development challenges to high performance simulations. One common development approach is to re-engineer the code for each new target architecture in order to maximize performance. However, this re-engineering effort is no longer practical due to increasing heterogeneous hardware. Adding support for a single family of GPUs alone poses a significant challenge. Supporting each major vendor's hardware and software stacks takes valuable developer time away from optimizing and enhancing simulation capabilities. Moving forward, the community must modernize the code development process in order to achieve the greatest scientific output.
In this work, we examine the challenges posed by emerging heterogeneous hardware. These challenges include developing performance portable code, leveraging hardware features targeting AI/ML for HPC applications, and difficulties managing limited I/O resources while checkpointing. To address these challenges we present a modernization approach for scientific software that ensures the following. Attain high performance and portability across architectures using the Kokkos portability framework in addition to optimizations to memory layout, sorting algorithms, and vectorization. Leverage alternative number formats such as half-precision and fixed-point to maximize usage of the limited memory on GPUs and enable larger simulations. Reduce IO overhead and storage requirements through the identification and elimination of spatial-temporal redundancy in application data.
In this work, we examine the challenges posed by emerging heterogeneous hardware. These challenges include developing performance portable code, leveraging hardware features targeting AI/ML for HPC applications, and difficulties managing limited I/O resources while checkpointing. To address these challenges we present a modernization approach for scientific software that ensures the following. Attain high performance and portability across architectures using the Kokkos portability framework in addition to optimizations to memory layout, sorting algorithms, and vectorization. Leverage alternative number formats such as half-precision and fixed-point to maximize usage of the limited memory on GPUs and enable larger simulations. Reduce IO overhead and storage requirements through the identification and elimination of spatial-temporal redundancy in application data.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Heterogeneous Computing
Software Engineering
TP
XO/EX
Archive
view
Hide Details

Charged Particle Track Reconstruction Algorithms for Massively Parallel Systems
DescriptionThe reconstruction of the trajectories of charged particles through detector experiments is a core computational task in the domain of high-energy physics. Upcoming upgrades to accelerators such as the Large Hadron Collider as well as to experiments like ATLAS threaten to render existing CPU-based approaches to track reconstruction insufficient, and the use of massively parallel systems - GPGPUs in particular - is an important opportunity to meet future data processing requirements. In my thesis, I investigate the feasibility of GPGPU-based track reconstruction from performance engineering perspective: I focus on structured analysis of application performance, the development of statistical and analytical models of performance, methods for mitigating the challenges of GPGPU programming, and the design and implementation of novel track reconstruction algorithms. The key contributions of my thesis include the development of novel algorithms for hit clustering, seed finding, and combinatorial Kalman filtering, key parts of the track reconstruction process. These algorithms suffer from significant load imbalance and thread divergence, and I have developed a novel statistical method for estimating the performance effects of this, as well as to guide optimization through thread refinement and coarsening. I have developed a method for the automated design space exploration of data storage methods for magnetic fields, which play a crucial role in track reconstruction. Furthermore, I have developed an evolutionary method for finding layouts for multi-dimensional arrays in hierarchical memory systems. My thesis will be concluded by a comprehensive study of the performance of track reconstruction, as guided by the aforementioned research.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Accelerators
Applications
TP
XO/EX
Archive
view
Hide Details
Design Automation Tools and Software for Quantum Computing
DescriptionQuantum computing promises to solve problems beyond the reach of today’s machines, but it requires efficient and reliable software tools to realize its potential. This poster gives an overview of various contributions towards design automation methods and software for quantum computing that leverage existing knowledge and expertise in classical circuit and system design. It focuses on three major tasks: simulation, compilation, and verification of quantum circuits. The proposed solutions demonstrate significant improvements in efficiency, scalability, and reliability for all tasks and constitute the backbone of the Munich Quantum Toolkit (MQT), a collection of open-source tools for quantum computing. The respective solutions advance the state of the art in quantum computing and illustrate the benefits of design automation methods for this emerging field.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Quantum Computing
TP
XO/EX
Archive
view
Hide Details
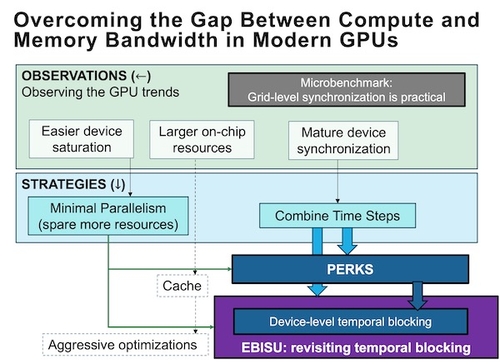
Overcoming the Gap between Compute and Memory Bandwidth in Modern GPUs
DescriptionThe imbalance between compute and memory bandwidth has been a long-standing issue. Despite efforts to address it, the gap between them is still widening. This has led to the categorization of many applications as memory-bound kernels.
This dissertation centers on memory-bound kernels, with a particular emphasis on Graphics Processing Units (GPUs), given their rising prevalence in High-Performance Computing (HPC) systems.
In this dissertation, we initially focus on the evolution trend of GPU development in the last decades. Examples include cooperative groups (i.e., device-wide barriers), asynchronous copy of shared memory (i.e., hardware prefetching), low(er) latency of operations, and larger volume of on-chip resources (register files and L1 cache).
This dissertation seeks to utilize the latest GPU features to optimize memory-bound kernels. Specifically, we propose extending the kernel's lifetime across the time steps and taking advantage of the large volume of on-chip resources (i.e., register files and scratchpad memory) in reducing or eliminating traffic to the device memory. Furthermore, we champion a minimum level of parallelism to maximize the available on-chip resources.
Based on the strategies, we propose a general execution model for running memory-bound iterative GPU kernels: PERsistent KernelS (PERKS) and a novel temporal blocking method, EBISU. Evaluations have shown outstanding performance in the latest GPU architectures compared with counterpart state-of-the-art implementations.
This dissertation centers on memory-bound kernels, with a particular emphasis on Graphics Processing Units (GPUs), given their rising prevalence in High-Performance Computing (HPC) systems.
In this dissertation, we initially focus on the evolution trend of GPU development in the last decades. Examples include cooperative groups (i.e., device-wide barriers), asynchronous copy of shared memory (i.e., hardware prefetching), low(er) latency of operations, and larger volume of on-chip resources (register files and L1 cache).
This dissertation seeks to utilize the latest GPU features to optimize memory-bound kernels. Specifically, we propose extending the kernel's lifetime across the time steps and taking advantage of the large volume of on-chip resources (i.e., register files and scratchpad memory) in reducing or eliminating traffic to the device memory. Furthermore, we champion a minimum level of parallelism to maximize the available on-chip resources.
Based on the strategies, we propose a general execution model for running memory-bound iterative GPU kernels: PERsistent KernelS (PERKS) and a novel temporal blocking method, EBISU. Evaluations have shown outstanding performance in the latest GPU architectures compared with counterpart state-of-the-art implementations.
Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Accelerators
TP
XO/EX
Archive
view
Hide Details
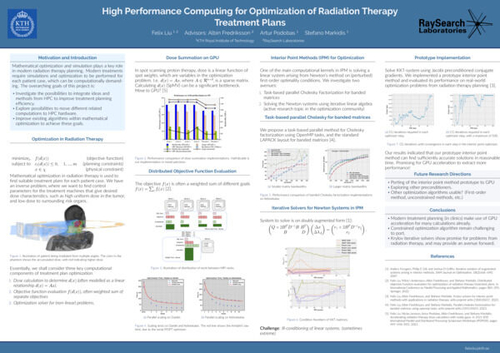
High Performance Computing for Optimization of Radiation Therapy Treatment Plans
DescriptionModern radiation therapy relies heavily on computational methods to design optimal treatment plans (control parameters for the treatment machine) for individual patients. These parameters are determined by constructing and solving a mathematical optimization problem. Ultimately, the goal is to create treatment plans for each patient such that a high dose is delivered to the tumor, while sparing surrounding healthy tissue as much as possible. Solving the optimization problem can be computationally expensive, as it requires both a method to compute the delivered dose in the patient and an algorithm to solve a (in general) constrained and nonlinear optimization problem.
The goal of this thesis project has been to investigate the use of HPC hardware and methods to accelerate the computational workflow in radiation therapy treatment planning. First, we propose two methods to bring the optimization to HPC hardware using GPU acceleration and distributed computing for dose summation and objective function calculation respectively. We show that our methods achieve competitive performance compared to state-of-the-art libraries and scale well, up to the Amdahl’s law limit.
Then, we investigate methods to accelerate interior point methods, a popular algorithm for constrained optimization. We investigate the use of iterative Krylov subspace linear solvers to solve Newton systems from interior point methods and show that we can compute solutions in reasonable time for our problems, in spite of extreme ill-conditioning. This approach presents one avenue by which constrained optimization solvers for radiation therapy could be ported to GPU accelerators.
The goal of this thesis project has been to investigate the use of HPC hardware and methods to accelerate the computational workflow in radiation therapy treatment planning. First, we propose two methods to bring the optimization to HPC hardware using GPU acceleration and distributed computing for dose summation and objective function calculation respectively. We show that our methods achieve competitive performance compared to state-of-the-art libraries and scale well, up to the Amdahl’s law limit.
Then, we investigate methods to accelerate interior point methods, a popular algorithm for constrained optimization. We investigate the use of iterative Krylov subspace linear solvers to solve Newton systems from interior point methods and show that we can compute solutions in reasonable time for our problems, in spite of extreme ill-conditioning. This approach presents one avenue by which constrained optimization solvers for radiation therapy could be ported to GPU accelerators.

Event Type
Doctoral Showcase
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationE Concourse
Applications
TP
XO/EX
Archive
view
Tuesday, 14 November 2023 10am-5pm D Concourse
Hide Details

Conversing Faults: The 2019 Ridgecrest Earthquake
DescriptionThe 2019 Ridgecrest earthquakes occurred in a complex system of fault lines in the Mojave desert. Separated by 34 hours, the earthquakes were caused by ruptures in separate but nearby faults. In this study of the geophysical processes underlying these events the surface, known faults and the volumetric subsurface are modeled on HPC systems. Visualization techniques are used to analyze the simulation results in their three-dimensional context.
Event Type
Posters
Scientific Visualization & Data Analytics Showcase
TimeTuesday, 14 November 202310am - 5pm MST
LocationD Concourse
Data Analysis, Visualization, and Storage
HPC in Society
Modeling and Simulation
Visualization
TP
XO/EX
Archive
view
LinksVisualization
Hide Details

A Journey to the Center of the Milky Way: Stellar Orbits around Its Central Black Hole
DescriptionThe Advanced Visualization Lab at the NCSA created a cinematic scientific visualization showing a flight through the Milky Way galaxy, to the galactic center where stars are orbiting around a supermassive black hole. The tour summarizes results from Andrea Ghez's Galactic Center Group: their study of the motions of stars around the Milky Way's central black hole reveals a rich and surprising environment, with hot young stars (coded as purple) where few were expected to be, many orbiting in a common plane; a paucity of cooler old stars (yellow); a population of unexpected "G-object" dusty stars (red); and an eclipsing binary star (teal). The black hole itself, shrouded in mystery, is seen only as a tiny faint twinkling radio source. But the movement of these nearby stars, especially the S0-2 "hero" (pale blue ellipse), probe the black hole's gravity, exposing its massive presence.
Authors

Event Type
Posters
Scientific Visualization & Data Analytics Showcase
TimeTuesday, 14 November 202310am - 5pm MST
LocationD Concourse
Data Analysis, Visualization, and Storage
Modeling and Simulation
Visualization
TP
XO/EX
Archive
view
LinksVisualization
Hide Details

Visualizing Megafires: How AI Can Be Used to Drive Wildfire Simulations with Better Predictive Skill
DescriptionThe East Troublesome Wildfire was the fourth largest wildfire to date in Colorado history, igniting on October 14, 2020. Driven by low humidity and high winds, the wildfire spread to over 200,000 acres in nine days, with 87,000 of those acres being burnt in a single 24 hour period. Wildfire simulations and forecasts help decision-makers issue evacuation orders and inform response teams, but these simulations depend on accurate variable inputs to produce trustworthy results. These wildfire visualizations demonstrate new AI tools developed at the National Center for Atmospheric Research (NCAR), which are producing superior wildfire simulation outputs than have been available in the past.
Event Type
Posters
Scientific Visualization & Data Analytics Showcase
TimeTuesday, 14 November 202310am - 5pm MST
LocationD Concourse
Data Analysis, Visualization, and Storage
HPC in Society
Modeling and Simulation
Visualization
TP
XO/EX
Archive
view
LinksVisualization
Hide Details

ExaWind at NREL: Upping the Ante
DescriptionThe objective of the ExaWind component of the Exascale Computing Project is to deliver many-turbine blade-resolved simulations in complex terrain. These simulations bring new challenges to both compute and analysis of the resulting data. In this paper/video, we visually explore the impact of ExaWind on wind simulations through two studies of a small wind farm under two atmospheric conditions. We then turn to analysis and review tools that visualization researchers at NREL use to answer the challenges that ExaWind brings.
Event Type
Posters
Scientific Visualization & Data Analytics Showcase
TimeTuesday, 14 November 202310am - 5pm MST
LocationD Concourse
Data Analysis, Visualization, and Storage
Exascale
HPC in Society
Modeling and Simulation
Visualization
TP
XO/EX
Archive
view
LinksVisualization
Hide Details

Visualizing the Impact of the Asian Summer Monsoon on the Composition of the Upper Troposphere and Lower Stratosphere
DescriptionWe present an explanatory-track visualization which utilizes multiple open-source graphics tools, including the C++ library OpenVDB and the 3D animation software Blender, to create a cinematic representation of simulation data generated in support of the Asian Summer Monsoon Chemical and Climate Impact Project (ACCLIP) campaign. After a brief summary of the project and data simulation, the process and techniques used to create the visualization are explained in detail.
Event Type
Posters
Scientific Visualization & Data Analytics Showcase
TimeTuesday, 14 November 202310am - 5pm MST
LocationD Concourse
Data Analysis, Visualization, and Storage
HPC in Society
Modeling and Simulation
Visualization
TP
XO/EX
Archive
view
LinksVisualization
Tuesday, 14 November 2023 10am-5pm DEF Concourse
Hide Details

Simultaneous Evaluation of Mindful Fault Checking across the CPU and GPU
DescriptionThis work comprehensively analyzes the overhead when implementing fault-checking algorithms for sparse preconditioned conjugate gradient (PCG) solvers on many-core and GPU-accelerated systems. Our objective is to selectively utilize GPUs for duplicate calculations based on the numerical properties of the sparse matrices to enhance the reliability and performance of linear system solutions. Enabling the ability to rely on the relatively underutilized CPU for fault detection improves scientific applications' ability to efficiently manage their resources on large-scale systems. By leveraging existing fault-checking techniques, we validate calculations and address potential numerical instabilities or precision-related issues during iterative solving. Through extensive experimentation on real hardware, we demonstrate the effectiveness of the conjugate gradient algorithm in providing accurate and reliable solutions for large linear systems.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
ProxyStreams: Leveraging Lightweight Proxies for Portable Streams
DescriptionA novel streaming approach is introduced for Python, leveraging the ProxyStore system to facilitate the exchange of stream references across distributed systems. This approach utilizes generators to efficiently publish and consume messages from streams. The extensible backend connector interface of ProxyStore enables support for diverse communication mechanisms, such as transitioning from ZMQ to RDMA. Performance results highlight the capability to perform data PUT and GET operations on streams with minimal overhead and high efficiency.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
A Comparison of Deep and Shallow Residual Networks for Medical Imaging Classification
DescriptionThe complexity and parameters of mainstream large models are increasing rapidly. For example, the increasingly popular large language models (e.g., ChatGPT) have billions of parameters. While this has led to performance improvements, the performance gains for simple tasks may be unacceptable for the additional cost. We apply residual networks of three different depths and evaluate them extensively on the MedMNIST pneumonia dataset. Experimental results show that smaller models can achieve satisfactory performance at significantly lower costs than larger models.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
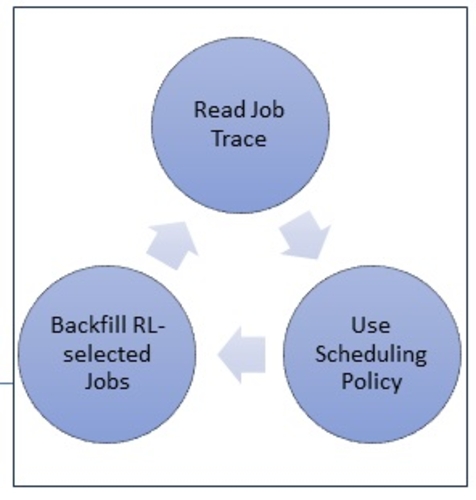
A Reinforcement Learning-Based Backfilling Strategy for HPC Batch Jobs
DescriptionHigh Performance Computing (HPC) systems are essential for various scientific fields, and effective job scheduling is crucial for their performance. Traditional backfilling techniques, such as EASY-backfilling, rely on user-submitted runtime estimates, which can be inaccurate and lead to suboptimal scheduling. This poster presents RL-Backfiller, a novel reinforcement learning (RL) based approach to improve HPC job scheduling. Our method incorporates RL to make better backfilling decisions, independent of user-submitted runtime estimates. We trained RL-Backfiller on the synthetic Lublin-256 workload and tested it on the real SDSC-SP2 1998 workload. We show how RLBackfilling can learn effective backfilling strategies and outperform traditional EASY-backfilling and other heuristic combinations via trial-and-error on existing job traces. Our evaluation results show up to 17x better scheduling performance (based on average bounded job slowdown) compared to EASY-backfilling
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Road To Reliability: Optimizing Self-Driving Consistency With Real-Time Speed Data
DescriptionSelf-driving cars can potentially improve transportation efficiency and reduce human fatalities – provided they have access to significant processing power and large amounts of data. One popular approach for actualizing autonomous vehicles is using end-to-end learning, in which a machine learning model is trained on a large data set of real human driving. This poster shows how self-driving consistency can be improved using a Convolutional Neural Network (CNN) to predict current velocity. Our approach first reproduces an end-to-end learning result and then extends it with real-time speed data as additional model input.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Using Deep Neural Networks to Classify Hot-Cold Data Storage
DescriptionThe Scientific Data and Computing Center (SDCC) at Brookhaven National Laboratory manages a data storage system with millions of files totaling petabytes of data. To optimize costs, they use a multi-tiered storage approach based on data temperature, storing infrequently accessed ("cold") data on cheaper technologies like Blu-ray disks or tape drives, and frequently accessed ("hot") data on faster but costlier mediums like Hard Disk Drives or Solid State Drives. Current data migration decisions rely on manual human judgment supported by simple algorithms not suitable for long-term predictions. To address this, our project aims to automate the process by training a deep neural network (DNN) on file metadata to predict data temperature upon upload. The model achieved promising initial results, with a 90.53% general accuracy in predicting data temperature. This automation could significantly improve the management and distribution of the vast research data generated at BNL.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Scaling Studies for Efficient Parameter Search and Parallelism for Large Language Model Pretraining
DescriptionAI accelerator processing and memory constraints largely dictate the scale in which machine learning workloads (training and inference) can be executed within a desirable time frame. Training a transformer-based model requires the utilization of HPC harnessed through inherent parallelism embedded in processor design, to deliberate modification of neural networks to increase concurrency during training and inference. Our model is the culmination of different performance tests seeking the ideal combination of frameworks and configurations for training a 13-billion-parameter translation model for foreign languages. We performed ETL over the corpus, which involved training a balanced interleaved dataset. We investigated the impact of batch size, learning rate, and different forms of precision on model training time, accuracy, and memory consumption. We use DeepSpeed stage 3 and Huggingface accelerate to parallelize our model. Our model, based on the mT5 architecture, is trained on the mC4 and language-specific datasets, enabling question-answering in the fine-tuning process.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Dynamic and First-Class Priorities
DescriptionInteractive parallel programs have varying responsiveness requirements for tasks of differing urgency, which has been met with the solution of thread priorities to determine the tasks' allocation of processor time. Previous priority-based language models limit the span of entire threads to a single priority. Given an approaching real-time deadline, tasks are unable to shift to a higher priority in order to match the changing requirements. We design a type system that enforces thread priorities and allows dynamic prioritization, treating priorities as first-class to reduce code complexity. We create a dependency graph-based cost model for our system and define strong well-formedness to exclude unwanted priority inversions. We then prove that programs under our type system produce strongly well-formed graphs.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
How Much Noise Is Enough: On Privacy, Security, and Accuracy Trade-Offs in Differentially Private Federated Learning
DescriptionCentralized machine learning techniques have caused privacy concerns for users. Federated Learning~(FL) mitigates this as a decentralized training system where no raw data are communicated across the network to a centralized server. Instead, the machine learning model is trained locally on each device and they send the locally-trained model weights to a central server to aggregate. However, there are critical challenges with FL. Security issues plague FL, such as model poisoning via label flipping. Additionally, there even exist privacy concerns via data leakage by reconstruction of weights. In this work, we apply differential privacy (which adds noise to the model weights before sending across the network) as an added privacy measure to protect sensitive data from being reconstructed. Through this research, we study the effects of differential privacy on FL with respect to security and privacy trade-offs.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
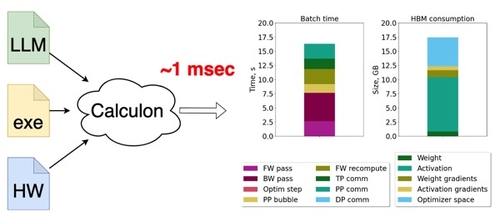
Scaling Infrastructure to Support Multi-Trillion Parameter LLM Training
DescriptionThis poster discusses efficient system designs for Large Language Model (LLM) scaling to up to 128 trillion parameters. We use a comprehensive analytical performance model to analyze how such models could be trained on current systems while maintaining 75% Model FLOPS Utilization (MFU). We first show how tensor offloading alone can be used to dramatically increase the size of trainable LLMs. We analyze performance bottlenecks when scaling on systems up to 16,384 GPUs and with models up to 128T parameters. Our findings suggest that current H100 GPUs with 80 GiB of HBM enabled with 512 GiB of tensor offloading capacity allows scaling to 11T-parameter LLMs; and getting to 128T parameters requires 120 GiB of HBM and 2 TiB of offloading memory, yielding 75%+ MFU, which is uncommon even when training much smaller LLMs today.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
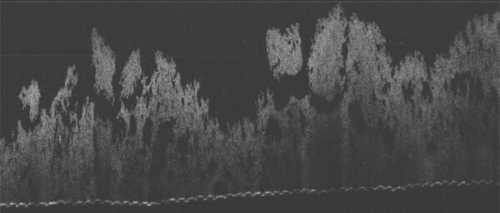
Lossy and Lossless Compression for BioFilm Optical Coherence Tomography (OCT)
DescriptionOptical Coherence Tomography (OCT) can be used as a fast and non-destructive technology for bacterial biofilm imaging. However, OCT generates approximately 100 GB per flow cell, which complicates storage and data sharing. Data reduction can reduce data complications by reducing the overhead and the amount of data transferred. This work leverages the similarities between layers of OCT images to minimize the data in order to improve compression. This paper evaluates the 5 lossless and 2 lossy state-of-the-art compressors to reduce the OCT data. The reduction techniques are evaluated to determine which compressor has the most significant compression ratio while maintaining a strong bandwidth and minimal image distortion. Results show that SZ with frame before pre-processing is able to achieve the highest CR of 204.6x on its higher error bounds. The maximum compression bandwidth SZ on higher error bounds is ~41MB/s, for decompression bandwidth, it is able to outperform ZFP achieving.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
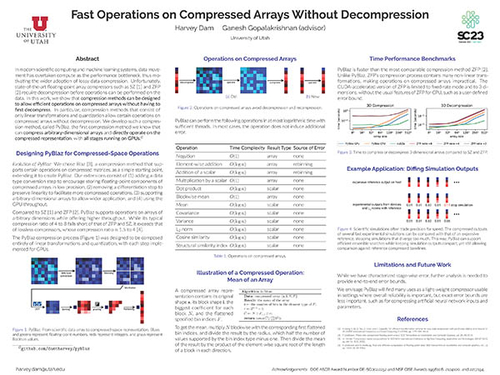
Fast Operations on Compressed Arrays without Decompression
DescriptionIn modern scientific computing and machine learning systems, data movement has overtaken compute as the performance bottleneck, thus motivating the wider adoption of lossy data compression. Unfortunately, state-of-the-art floating-point array compressors such as SZ and ZFP require decompression before operations can be performed on the data. In this work, our contribution is to show that compression methods can be designed to allow efficient operations on compressed arrays without having to first decompress. In particular, compression methods that consist of only linear transformations and quantization allow certain operations on compressed arrays without decompression. We develop such a compression method, called PyBlaz, the first compression method we know that can compress arbitrary-dimensional arrays and directly operate on the compressed representation, with all stages running on GPUs.
In the poster session, I will provide details about each compression step, several compressed-spaced operations, and our ongoing performance and application experiments.
In the poster session, I will provide details about each compression step, several compressed-spaced operations, and our ongoing performance and application experiments.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Utilizing Large Language Models for Disease Phenotyping in Obstructive Sleep Apnea
DescriptionObstructive sleep apnea (OSA) impacts millions, linking to severe complications yet understanding its influence on comorbidities lags. Complications can be avoided by using expensive continuous positive airway pressure (CPAP) machines, but physicians cannot identify those at risk. Large language models (LLMs) have recently made impressive advancements in sequence modeling, and clinical applications are quickly emerging. However, the medical relevance of pre-trained LLM latent spaces remains uncertain.
This study gauges 12 pre-trained clinical LLMs, clustering OSA-related phenotypes and comorbidities (atrial fibrillation, coronary artery disease, heart failure, hypertension, stroke, type 2 diabetes). Using 40 A100 GPUs on NERSC’s Perlmutter, document-level embeddings for 331,793 MIMIC-IV discharge reports were computed for each LLM. K-Means models were ranked by clustering entropy of phenotype classes, guiding model selection. The top models successfully subset patients with similar histories and outcomes. This work will support ongoing OSA research by identifying phenotypes and assist physicians by informing CPAP allocation.
This study gauges 12 pre-trained clinical LLMs, clustering OSA-related phenotypes and comorbidities (atrial fibrillation, coronary artery disease, heart failure, hypertension, stroke, type 2 diabetes). Using 40 A100 GPUs on NERSC’s Perlmutter, document-level embeddings for 331,793 MIMIC-IV discharge reports were computed for each LLM. K-Means models were ranked by clustering entropy of phenotype classes, guiding model selection. The top models successfully subset patients with similar histories and outcomes. This work will support ongoing OSA research by identifying phenotypes and assist physicians by informing CPAP allocation.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Enabling Transparent, High-Throughput Data Movement for Scientific Workflows on HPC Systems
DescriptionThis poster presents the DYnamic and Asynchronous Data Streamliner (DYAD) middleware that provides an efficient and transparent method for data movement in scientific workflows based on the producer-consumer paradigm. We develop DYAD on top of Flux, a fully hierarchical HPC workload manager, and Unified Communication X (UCX), a unified framework for networking on HPC systems. We measure DYAD's performance with a suite of mini-apps and show how it outperforms traditional methods for data transfer while providing a higher level of transparency.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Better Data Splits for Machine Learning with Astartes
DescriptionMachine Learning (ML) has become an increasingly popular tool to accelerate traditional workflows. Critical to the use of ML is the process of splitting datasets into training, validation, and testing subsets to develop and evaluate models. Common practice is to assign these subsets randomly. Although this approach is fast, it only measures a model's capacity to interpolate. These testing errors may be overly optimistic on out-of-scope data; thus, there is a growing need to easily measure performance for extrapolation tasks. To address this issue, we report astartes, an open-source Python package that implements many similarity- and distance-based algorithms to partition data into more challenging splits. This poster focuses on use-cases within cheminformatics. However, astartes operates on arbitrary vectors, so its principals and workflow are generalizable to other ML domains as well. astartes is available via the Python package managers pip and conda and is publicly hosted on GitHub (github.com/JacksonBurns/astartes).
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
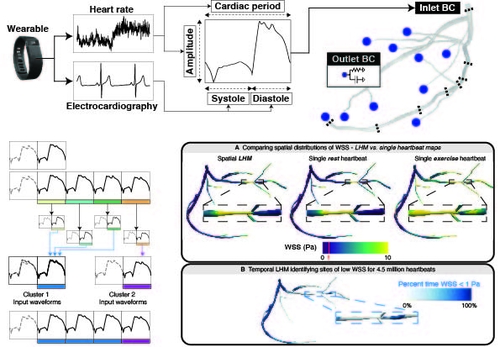
Cloud Computing at Scale: Tracking 4.5 Million Heartbeats of 3D Coronary Flow via the Longitudinal Hemodynamic Mapping Framework
DescriptionTracking hemodynamic responses to treatment and stimuli for long periods is a grand challenge. Moving from established single-heartbeat technology to longitudinal profiles would require continuous data reflecting a patient's evolving state, methods to extend the temporal domain that could be feasibly computed, and high-throughput resources. Although personalized models can accurately measure 3D hemodynamics over single heartbeats, state-of-the-art methods would require centuries of runtime on leadership-class systems to simulate one day of activity. We are establishing the Longitudinal Hemodynamic Mapping Framework (LHMF), which combines patient-specific models, wearables, and cloud computing to enable the first digital twins that capture longitudinal hemodynamic maps (LHMs). We demonstrate validity through comparison with ground truth data for 750 beats. We applied LHMF to generate the first LHM of coronary arteries spanning 4.5 million heartbeats. LHMF relies on an initial fixed set of representative simulations to enable the computationally tractable creation of LHM over heterogeneous systems.

Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
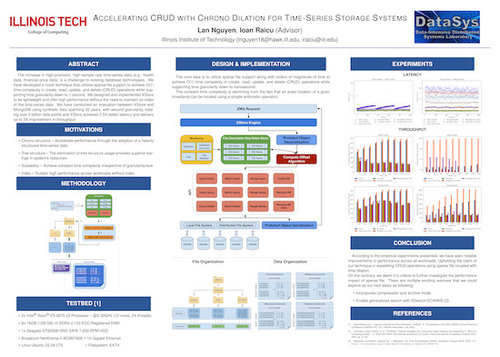
Accelerating CRUD with Chrono Dilation for Time-Series Storage Systems
DescriptionIn recent years, we have seen an un-precedented growth of data in our daily lives ranging from health data from an Apple Watch, financial stock price data, volatile crypto-currency data, to diagnostic data of nuclear/rocket simulations. The increase in high-precision, high-sample-rate time-series data is a challenge to existing database technologies. We have developed a novel technique that utilizes sparse-file support to achieve O(1) time complexity in create, read, update, and delete (CRUD) operations while supporting time granularity down to 1-second. We designed and implemented XStore to be lightweight and offer high performance without the need to maintain an index of the time-series data. We have conducted a detailed evaluation between XStore and existing best-of-breed systems such as MongoDB using synthetic data spanning 20 years, with second granularity, totaling over 5 billion datapoints. Through empirical experiments against MongoDB, XStore achieves 2.5X better latency and delivers up to 3X improvement in throughput.

Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
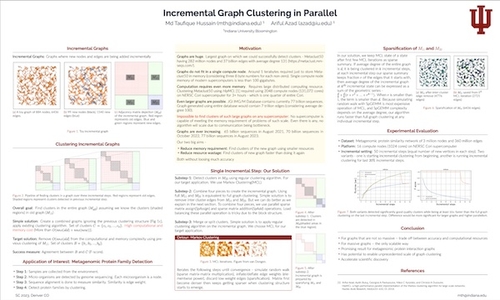
Incremental Graph Clustering in Parallel
DescriptionWe develop a distributed memory graph clustering algorithm to find clusters in a graph where new nodes and edges are being added incrementally. At each stage of the algorithm, we maintain a summary of the clustered graph computed from all incremental batches received thus far. As we receive a new batch of nodes and edges, we cluster the new graph and merge new clusters with the previous summary clusters. We use sparse linear algebra to perform these operations. Our algorithm would make it possible to find clusters in very large graphs for which regular graph clustering algorithms could not run due to computation/communication bottlenecks.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
NetCDFaster: A Geospatial Cyberinfrastructure for Multi-Dimensional Scientific Datasets Full-Stack I/O and Visualization
DescriptionNetCDF's original design included a portable file format and an intuitive application programming interface (API). However, the current NetCDF framework and its derived libraries lack efficient support for querying and visualizing data subsets with low memory use and time cost. Therefore, a full-stack solution to handle and display multidimensional data frames in NetCDF must be developed to meet the research needs. In this project, a next-generation full-stack tool, “NetCDFaster,” was developed to accelerate the reading and viewing of NetCDF data. This tool was derived from serial and parallel interfaces built on MPI-IO. The test results showed that processing time and memory usage were significantly improved than conventional methods.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
A Heterogeneous, In Transit Approach for Large Scale Cellular Modeling
DescriptionThe field of in silico cellular modeling has made notable strides in number of cells that can be simultaneously modeled. While computational capabilities have grown exponentially, I/O performance has lagged behind. To address this issue, we present an in-transit approach to enable in situ visualization and analysis of large-scale fluid-structure-interaction models on leadership-class systems. We delineate the proposed framework and demonstrate the feasibility of this approach by measuring overhead introduced. The proposed framework provides a valuable tool for both at-scale debugging and enabling scientific discovery, which would be difficult to achieve otherwise.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
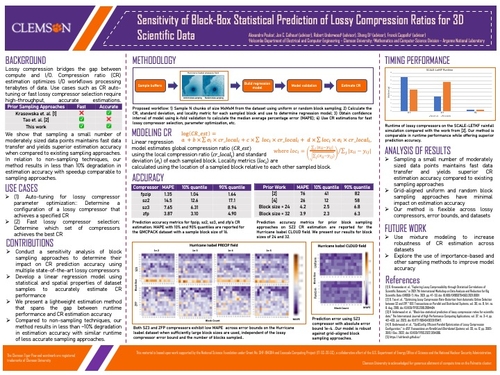
Sensitivity of Black-Box Statistical Prediction of Lossy Compression Ratios for 3D Scientific Data
DescriptionCompression ratio estimation is an important optimization of I/O workflows processing terabytes of data. Applications such as compression auto-tuning or lossy compressor selection require a high-throughput, accurate estimation. Prior works that utilize sampling are fast but inaccurate, while approaches which do not use sampling are highly accurate but slow. Through sensitivity analysis we show that sampling a small number of moderately sized data blocks maintains fast data transfer and yields superior estimation accuracy compared to existing sampling approaches, and we use this to construct a new fast and accurate sampling method. In relation to non-sampling techniques, our method results in less than 10% degradation in estimation accuracy, while still maintaining the high throughput of the less accurate sampling methods.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Seeing the Trees for the Forest: Describing HPC Filesystem Trees with the Grand Unified File-Index (GUFI)
DescriptionHigh performance computing (HPC) filesystems are extremely large, complex, and difficult to manage with existing tools. It is challenging for HPC administrators to describe the current structure of their filesystems, predict how they will change over time, and the requirements for future filesystems as they continue to evolve. Previous studies of filesystem characteristics largely predate the modern HPC filesystems of the last decade. The Grand Unified File Index (GUFI) was used to collect the data used to compute the characteristics of six HPC filesystems indexes from Los Alamos National Laboratory (LANL) representing 2.8 PB of data, containing 36 million directories and 600 million files. We present a methodology using GUFI to characterize the shape of HPC filesystems to help system administrators to understand their key characteristics.
This document has been approved for public release under LA-UR-23-28958.
This document has been approved for public release under LA-UR-23-28958.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Cray EX40 Cluster Intrusion Detection System
DescriptionAnalysis of a High-Performance Computing cluster’s external network traffic provides the opportunity to identify security issues, cluster misuse, or configuration problems without reducing performance. This project captured the external network traffic to and from a Cray EX40 cluster over three months and analyzed it utilizing two open-source intrusion detection tools, Suricata and Zeek. The tool alerts were sent to Splunk via rsyslog for parsing and analysis. Several security concerns were identified, including excessive failed authentication attempts and the use of four invalid certificates. Multiple cluster configuration issues were also identified, including recurrent anomalous Domain Name Service (DNS) queries which comprised 97% of all DNS traffic and incorrectly routed outbound Hypertext Transfer Protocol traffic. The port mirror architecture combined with network intrusion detection tools offered valuable insight into security concerns and several configuration issues. Excessive failed authentication attempts and a switch DNS configuration issue were both resolved by this project.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Job Level Communication-Avoiding Detection and Correction of Silent Data Corruption in HPC Applications
DescriptionDetecting and correcting Silent Data Corruption (SDC) is of high interest for many HPC applications due to the dramatic consequences such undetected computation errors can have. Additionally, going into the exascale era of computing, SDC error rates are only increasing with growing system sizes. State of the art methods based on instruction duplication suffer from only partial error coverage, significant synchronization overhead and strong coupling of computation and validation.
This work proposes a novel communication-avoiding approach of detecting and mitigating SDCs at the job level within the workload manager, assuming a directed acyclic graph (DAG) job model. Each job only communicates a locally generated output data hash. Computation and validation are decoupled as separately schedulable jobs and dependency stalling is avoided with a special error recovery method. The implementation of this project within the SLURM workload manager is in progress and key design aspects are outlined.
This work proposes a novel communication-avoiding approach of detecting and mitigating SDCs at the job level within the workload manager, assuming a directed acyclic graph (DAG) job model. Each job only communicates a locally generated output data hash. Computation and validation are decoupled as separately schedulable jobs and dependency stalling is avoided with a special error recovery method. The implementation of this project within the SLURM workload manager is in progress and key design aspects are outlined.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Case Study for Performance Portability of GPU Programming Frameworks for Hemodynamic Simulations
DescriptionPreparing for the deployment of large scientific and engineering codes on GPU-dense exascale systems is made challenging by the unprecedented diversity of vendor hardware and programming model alternatives for offload acceleration. To leverage the exaflops of GPUs from Frontier (AMD) and Aurora (Intel), users of high performance computing (HPC) legacy codes originally written to target NVIDIA GPUs will have to make decisions with implications regarding porting effort, performance, and code maintainability. To facilitate HPC users navigating this space, we have established a pipeline that combines generalized GPU performance models with proxy applications to evaluate the performance portability of a massively parallel computational fluid dynamics (CFD) code in CUDA, SYCL, HIP, and Kokkos with backends on current NVIDIA-based machines as well as testbeds for Aurora (Intel) and Frontier (AMD). We demonstrate the utility of predictive models and proxy applications in gauging performance bounds and guiding hand-tuning efforts.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Fast Checkpointing of Large Language Models with TensorStore CHFS
DescriptionThe frequency of checkpoint creation in large language models is limited by the write bandwidth to a parallel file system. In this study, we aim to reduce the checkpoint creation time by writing to the Intel Optane Persistent Memory installed on the compute nodes.
We propose TensorStore CHFS, a storage driver that adds an ad hoc parallel file system CHFS to the TensorStore. The proposed method succeeded in increasing the checkpoint creation bandwidth of the T5 1.1 model by 4.5 times on 32 nodes.
We propose TensorStore CHFS, a storage driver that adds an ad hoc parallel file system CHFS to the TensorStore. The proposed method succeeded in increasing the checkpoint creation bandwidth of the T5 1.1 model by 4.5 times on 32 nodes.
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
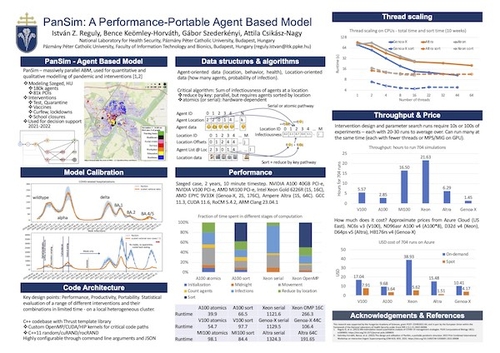
PanSim: A Performance-Portable Agent Based Model
SessionResearch Posters Display
DescriptionPanSim, a specialized agent-based model, was developed to analyze interventions against COVID-19. Implemented in C++ and Thrust, it is a highly performant and portable code. Here we focus on different algorithmic formulations for calculating cumulative values like infectiousness at different locations. A detailed comparison of time and efficiency on different CPUs and GPUs was conducted, revealing suboptimal parallel efficiency. The time to execute 704 simulations on each platform was evaluated, emphasizing overall throughput instead of latency for more taxing workloads. We benchmarked modern CPU and GPU architectures, revealing the superior performance of NVIDIA A100 and AMD Genoa-X platforms. Additionally, the monetary cost associated with executing the simulations was analyzed, presenting a contrasting landscape in on-demand and spot pricing. Ampere Altra platform emerged as the most cost-effective. The findings contribute to understanding the efficiency, time, and cost dynamics in modeling and provide insights for the practice of pandemic response planning.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
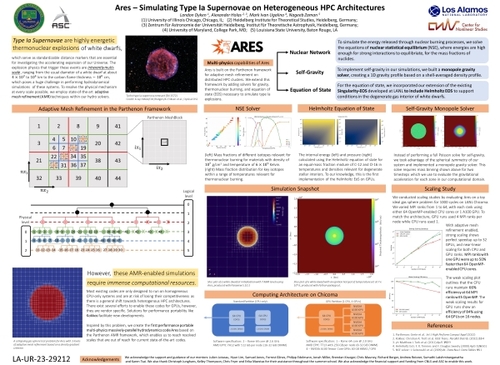
Ares – Simulating Type Ia Supernovae on Heterogeneous HPC Architectures
SessionResearch Posters Display
DescriptionType Ia Supernovae are highly luminous thermonuclear explosions of white dwarfs which serve as standardizable distance markers for investigating the accelerating expansion of our Universe. Most existing supernovae simulation codes are only designed to run on homogeneous CPU-only systems and do not take advantage of the increasing shift towards heterogeneous architectures in HPC. To address this, we present Ares, the first performance portable massively-parallel code for simulating thermonuclear burn fronts. By creating multi-physics modules using the Kokkos and Parthenon frameworks, we are able to scale supernovae simulations to distributed HPC clusters operating on any of CUDA, HIP, SYCL, HPX, OpenMP and serial backends. We evaluate our application by conducting weak and strong scaling studies on both CPU and GPU clusters, showing the efficiency of our method for a diverse set of targets.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Balancing Latency and Throughput of Distributed Inference by Interleaved Parallelism
SessionResearch Posters Display
DescriptionDistributed large model inference is still in a dilemma where balancing latency and throughput, or rather cost and effect. Tensor parallelism, while capable of optimizing latency, entails a substantial expenditure. Conversely, pipeline parallelism excels in throughput but falls short in minimizing execution time.
To address this challenge, we introduce a novel solution - interleaved parallelism. This approach interleaves computation and communication across requests. Our proposed runtime system harnesses GPU scheduling techniques to facilitate the overlapping of communication and computation kernels, thereby enabling this pioneering parallelism for distributed large model inference. Extensive evaluations show that our proposal outperforms existing parallelism approaches across models and devices, presenting the best latency and throughput in most cases.
To address this challenge, we introduce a novel solution - interleaved parallelism. This approach interleaves computation and communication across requests. Our proposed runtime system harnesses GPU scheduling techniques to facilitate the overlapping of communication and computation kernels, thereby enabling this pioneering parallelism for distributed large model inference. Extensive evaluations show that our proposal outperforms existing parallelism approaches across models and devices, presenting the best latency and throughput in most cases.
Authors

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Scalable Algorithms for Analyzing Large Dynamic Networks Using CANDY
SessionResearch Posters Display
DescriptionAs the dynamic network’s topology undergoes temporal alterations, associated graph properties must be updated to ensure their ac- curacy. Addressing this requirement efficiently in large dynamic networks led to the proposal of a generic framework, CANDY (Cyberinfrastructure for Accelerating Innovation in Network Dynamics). This paper expounds on the development of algorithms and subsequent performance improvements facilitated by CANDY.
Authors


Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Parallel Optimization Methods for Direct Numerical Simulation of High Reynolds Number Wall Turbulence with a Grid Size of 100 Billion
SessionResearch Posters Display
DescriptionDirect numerical simulation (DNS) is a technique that directly solves the fluid Navier-Stokes equations with high spatial and temporal resolutions. However, its utility in studying high Reynolds number (Re) wall turbulence of particular interest is limited by the rapidly growing grid size (i.e., the memory and computation requirement) with Re^3.
We present PowerLLEL, a high-performance finite difference solver tailored for the challenging DNS of incompressible wall turbulence at extreme scales. An adaptive multi-level parallelization strategy is proposed to fully exploit the multi-level parallelism of various architectures and enhance computational performance. The communication performance of global transpose and halo exchange is significantly improved by a tridiagonal solver based on the parallel diagonal dominant (PDD) algorithm and three RDMA-implemented communication optimizations. Strong scaling tests on the Tianhe-2A supercomputer show that PowerLLEL achieves nearly 92% parallel efficiency with up to 31,104 cores on a grid size of 143.3 billion.
We present PowerLLEL, a high-performance finite difference solver tailored for the challenging DNS of incompressible wall turbulence at extreme scales. An adaptive multi-level parallelization strategy is proposed to fully exploit the multi-level parallelism of various architectures and enhance computational performance. The communication performance of global transpose and halo exchange is significantly improved by a tridiagonal solver based on the parallel diagonal dominant (PDD) algorithm and three RDMA-implemented communication optimizations. Strong scaling tests on the Tianhe-2A supercomputer show that PowerLLEL achieves nearly 92% parallel efficiency with up to 31,104 cores on a grid size of 143.3 billion.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Performant Low-Order Matrix-Free Finite Element Kernels on GPE Architectures
SessionResearch Posters Display
DescriptionNumerical methods such as the Finite Element Method (FEM) have successfully leveraged the computational power of GPU accelerators. However, much of the effort around FEM on GPU’s has been focused on high order discretizations due to their higher arithmetic intensity and order of accuracy. For applications such as the simulation of geologic reservoirs, high levels of heterogeneity results in high-resolution grids characterized by highly discontinuous (cell-wise) material property fields. Additionally, the significant uncertainties typical of geologic reservoirs reduces the benefits of high order accuracy, and low order methods are typically employed. In this study, we present a strategy for implementing highly performant low-order matrix-free FEM operator kernels in the context of the conjugate gradient method. Performance results of the operator kernel are presented and are shown to compare favorably to matrix-based SpMV operators on V100, A100, and MI250X GPUs.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Introducing Prefetching and Data Compression to Accelerate Checkpointing for Inverse Seismic Problems
SessionResearch Posters Display
DescriptionRemote Time Migration (RTM) poses substantial computational challenges, demanding large memory and extended processing times. Our RTM implementation processes three-dimensional fields on multiple NVIDIA GPUs using the Revolve algorithm for checkpointing. However, transferring data between the host and GPU memory introduces a bottleneck.
We introduced a checkpoint prefetching mechanism to overcome this, anticipating memory transfers from host to GPU. Additionally, we integrated GPU data compression using the cuZFP library to reduce data transfer sizes further. The experimental results demonstrated significant performance improvements, achieving a speedup of 1.98x - 2.53x in our benchmark dataset. Prefetching + compression techniques together could reduce host-to-GPU memory transfers by up to 16x.
We introduced a checkpoint prefetching mechanism to overcome this, anticipating memory transfers from host to GPU. Additionally, we integrated GPU data compression using the cuZFP library to reduce data transfer sizes further. The experimental results demonstrated significant performance improvements, achieving a speedup of 1.98x - 2.53x in our benchmark dataset. Prefetching + compression techniques together could reduce host-to-GPU memory transfers by up to 16x.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
GPU-Accelerated Dense Covariance Matrix Generation for Spatial Statistics Applications
SessionResearch Posters Display
DescriptionLarge-scale parallel computing is crucial in Gaussian regressions to reduce the complexity of spatial statistics applications. The log-likelihood function is utilized to evaluate the Gaussian model for a set of measurements in N geographical locations. Several studies have shown a utilization of modern hardware to scale the log-likelihood function for handling large numbers of locations. ExaGeoStat is an example of software that allows parallel statistical parameter estimation from the log-likelihood function. However, generating a covariance matrix is mandatory and challenging when estimating the log-likelihood function. In ExaGeoStat, the generation process was performed on CPU hardware due to missing math functions in CUDA libraries, e.g., the modified Bessel function of the second kind. This study aims to optimize the generation process using GPU with two proposed generation schemes: pure GPU and hybrid. Our implementations demonstrate up to 6X speedup with pure GPU and up to 1.5X speedup with the hybrid scheme.
Authors



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
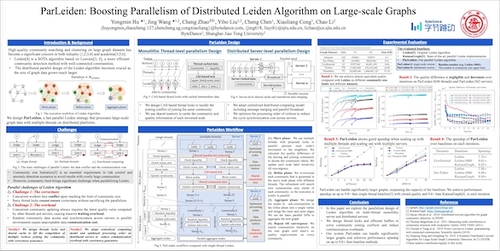
ParLeiden: Boosting Parallelism of Distributed Leiden Algorithm on Large-Scale Graphs
SessionResearch Posters Display
DescriptionLeiden algorithm has demonstrated superior efficacy compared to traditional Louvain algorithms in the field of community detection. However, parallelizing the Leiden algorithm while imposing community size limitations brings significant challenges in big data processing scenarios. We present ParLeiden, a pioneering parallel Leiden strategy designed for distributed environments. By thread locks and efficient buffers, we effectively resolve community joining conflicts and reduce communication overheads. We can run Leiden algorithm on large-scale graphs and achieve performance speedup on up to 9.8 times than baselines.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Scalable Reduced-Order Modeling for Three-Dimensional Turbulent Flow
SessionResearch Posters Display
DescriptionA neural network-based reduced order modeling method for three-dimensional turbulent flow simulation is proposed. This method was implemented as the scalable distributed learning on Fugaku. Our method constitutes a dimensional reduction using a convolutional-autoencoder-like neural network and the time evolution prediction using long short-term memory networks. The time evolution of the turbulent three-dimensional flow (e.g., Re=2.8×10^6) could be simulated at a significantly lower cost (approximately four orders of magnitude) without a major loss in accuracy. Using the single core memory group, our implementation shows 370 GFLOPS (24.28% of the peak performance) for the entire training loop and 753 GFLOPS (24.28% of the peak performance) for the convolution kernel. Our implementation scales up to 25,250 computational nodes (1,212,000 cores). Thus it shows 72.9 % of weak scaling performance (7.8 PFLOPS) for the entire training loop. On the other hand, the convolution routine shows 100.8% of weak scaling performance (113 PFLOPS).
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Unstructured Finite Element Models of Cardiac Electrophysiology Using a Deal.II-Based Library
SessionResearch Posters Display
DescriptionCardiovascular electrophysiology simulations often involve computationally expensive tasks due to the inherent multiphysics complexity of the problems. Additionally, the use of complex patient-specific geometries and biophysically-detailed ionic models adds to the system's complexity. To numerically solve such problems within reasonable timeframes, high-performance computing plays a crucial role. In this poster, we present a high-performance electrophysiology library specifically designed to address these demanding simulations. The library's routines support the use of linear, and quadratic tetrahedral elements. Moreover, our library offers a two-way coupling capability that enables interactions among multi-dimensional meshes. This important feature facilitates the simulation of electrical interactions between insulated regions of the heart, such as the atria and the ventricles. By enabling such coupling, the library aims to contribute to a more comprehensive understanding of the heart's electrophysiology and its intricate electrical behavior.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
A Methodology for Accelerating Variant Calling on GPU
SessionResearch Posters Display
DescriptionPointing out genetic mutations is pivotal to enable clinicians to prescribe personalized therapies to their patients. Genome Analysis ToolKit's HaplotypeCaller, relying on the Pair Hidden Markov Model (PairHMM) algorithm, is one of the most used applications to identify such variants. However, the PairHMM represents the bottleneck for this tool. Deploying such an algorithm on hardware accelerators represents a valuable solution. Nevertheless, State-of-the-Art designs do not have the flexibility to support the length variability of the input sequences and are not usable in real-life applicative scenarios. For these reasons, this work presents a GPU accelerator for the PairHMM capable of supporting sequences of any length, thanks to a dynamic memory swap methodology, overcoming the limitation of literature solutions. Our accelerator achieves an 8154× speedup over the software baseline, surpassing the most-performant State-of-the-Art design up to 1.6×.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Developing an Inverse Reinforcement Learning Methodology to Predict the Progression of Colorectal Cancer
SessionResearch Posters Display
DescriptionIn cancer biology, large amounts of high dimensional data (genomic, transcriptomic, proteomic, phenotypic, etc.) are required for any computationally relevant work. The problem is further complicated by the sheer size of the human genome, roughly three billion base pairs long. Therefore, computation is time-consuming and data-intensive. To solve this problem for human colorectal cancer, we are implementing a machine learning engine based on inverse reinforcement learning, and includes several different kinds of neural networks to perform data preparation, training, and prediction. Our work aims to reconstruct the progression of tumor development in a sample, and predict the next steps of its evolution, to aid in diagnosis and treatment. This poster will be presented as a work in progress methodology.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
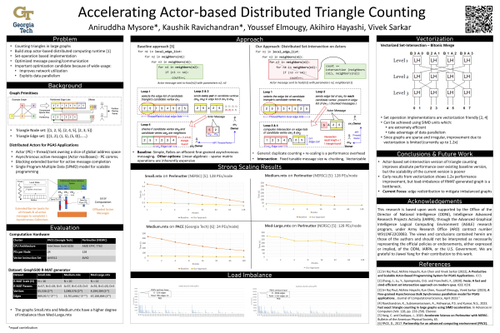
Accelerating Actor-Based Distributed Triangle Counting
SessionResearch Posters Display
DescriptionTriangle counting is a cornerstone operation in large graph analytics. It has been a challenging problem historically, owing to the irregular and dynamic nature of the algorithm, which not only inhibits compile-time optimizations, but also requires runtime optimizations such as message aggregation and load-imbalance mitigation. Popular triangle counting algorithms are either inherently slow, fail to take advantage of available vectorization in modern processors, or involve sparse matrix operations. With its support for fine-grained asynchronous messages, the Partitioned Global Address Space (PGAS) with the Actor model has been identified to be efficient for irregular applications. However, few triangle counting implementations have been optimally implemented on top of PGAS Actor runtimes. To address the above mentioned challenges, we propose a set-intersection-based implementation of a distributed triangle counting algorithm atop the PGAS Actor runtime. Evaluation of our approach on the PACE Phoenix cluster and the Perlmutter supercomputer shows encouraging results.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
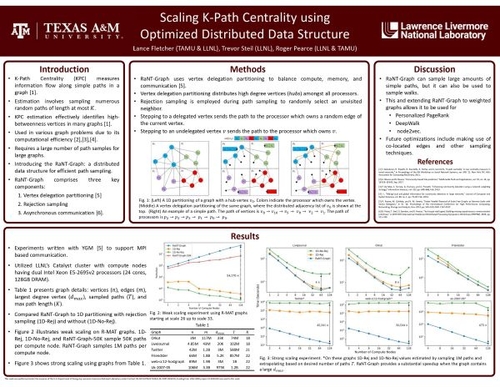
Scaling K-Path Centrality Using Optimized Distributed Data Structure
SessionResearch Posters Display
DescriptionK-Path centrality is based on the flow of information in a graph along simple paths of length at most K. This work addresses the computational cost of estimating K-path centrality in large-scale graphs by introducing the random neighbor traversal graph (RaNT-Graph). The distributed graph data structure employs a combination of vertex delegation partitioning and rejection sampling, enabling it to sample massive amounts of random paths on large scale-free graphs. We evaluate our approach by running experiments which demonstrate strong scaling on large real-world graphs. The RaNT-Graph approach achieved a 56,544x speedup over the baseline 1D partition implementation when estimating K-path centrality on a graph with 89 million vertices and 1.9 billion edges.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Simulating Quantum Systems with NWQ-Sim on HPC
SessionResearch Posters Display
DescriptionNWQ-Sim is a cutting-edge quantum system simulation environment designed to run on classical multi-node, multi-CPU/GPU heterogeneous HPC systems. In this work, we provide a brief overview of NWQ-Sim and its implementation in simulating quantum circuit applications, such as the transverse field Ising model. We also demonstrate how NWQ-Sim can be used to examine the effects of errors that occur on real quantum devices, using a combined device noise model. Moreover, NWQ-Sim is particularly well-suited for implementing variational quantum algorithms where circuits are dynamically generated. Therefore, we also illustrate this with the variational quantum eigensolver (VQE) for the Ising model. In both cases, NWQ-Sim's performance is comparable to or better than alternative simulators. We conclude that NWQ-Sim is a useful and flexible tool for simulating quantum circuits and algorithms, with performance advantages and noise-aware simulation capabilities.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
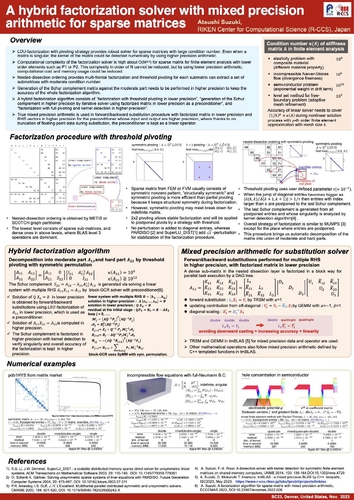
A Hybrid Factorization Solver with Mixed Precision Arithmetic for Sparse Matrices
SessionResearch Posters Display
DescriptionFor numerical simulations, linear system with large sparse matrix with high condition number needs to be solved. LDU-factorization with pivoting strategy provides robust solver for such system. Computational complexity of the factorization solver is high and cannot be reduced in framework of the direct solver, but by using lower precision arithmetic, computational cost and memory usage could be reduced. LDU-factorization uses recursive generation of the Schur complement matrix, but generation of the last one can be replaced by an iterative method. Here decomposition of the whole matrix into a union of the moderate and hard parts during factorization with threshold pivoting plays a key role. A new algorithm uses factorization in lower precision as a preconditioner for iterative solver in higher precision to generate the last Schur complement. True mixed precision arithmetic is used in forward/backward substitution for preconditioner with factorized matrix in lower precision and RHS vectors in higher.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Towards Enabling Digital Twins Capabilities for a Cloud Chamber
SessionResearch Posters Display
DescriptionParticle-resolved direct numerical simulations (PR-DNS), which resolve not only the smallest turbulent eddies but also track the development and motion of individual particles, are arguably an essential tool for exploring aerosol-cloud-turbulence interactions at the fundamental level. For instance, PR-DNS may complement experimental facilities designed to study key physical processes in a controlled environment and therefore serve as digital twins for such cloud chambers. In this poster we present our ongoing work aimed at enabling the use of a PR-DNS model for this purpose. We consider two approaches: traditional HPC techniques and emerging machine learning methods. Future research directions are outlined as well.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
High-Performance PMEM-Aware Collective I/Os
SessionResearch Posters Display
DescriptionCollective I/Os are widely used to transform small non-contiguous accesses into large contiguous accesses for parallel I/O optimization. The existing collective I/O techniques assume that computer memory is volatile. They are limited both by the size of the buffer, which must be small so data is not lost during a crash, and the communication overhead that occurs during collective I/O. PMIO is a proposed framework to utilize persistent memory (PMEM) for collective I/O, as opposed to DRAM. First, we utilize a log-structured buffer to take advantage of the non-volatility of PMEM. Second, we utilize larger buffers to take advantage of the larger space available on less expensive PMEM. Finally, we implement a two-phase merging algorithm to eliminate the communication overhead. The poster provides an overview of collective I/O and its problems, an introduction to PMEM, an outline of PMIO, and a brief discussion of PMIO's performance.



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
Architecture and Networks
I/O and File Systems
TP
XO/EX
Archive
view
Hide Details
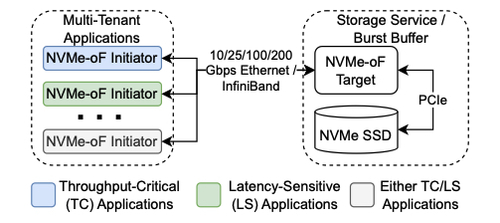
An Early Case Study with Multi-Tenancy Support in SPDK’s NVMe-over-Fabric Designs
SessionResearch Posters Display
DescriptionResource disaggregation is prevalent in datacenters since it provides high resource utilization when compared to servers dedicated to either compute, memory, or storage. NVMe-over-Fabrics (NVMe-oF) is the standardized protocol used for accessing disaggregated storage over the network. Currently, the NVMe-oF specification lacks any semantics to prioritize I/O requests based on different application needs. Since applications have varying goals — latency-sensitive or throughput-critical I/O — we need to design efficient schemes in order to allow applications to specify the type of performance they wish to achieve. Furthermore, with additional tenants, we need to provide the respective specified performance optimizations that each application requests, regardless of congestion. This is a challenging problem, as the current NVMe specification lacks semantics to support multi-tenancy. Our research poster brings awareness to the ways in which we can bring multi-tenancy support to the NVMe-oF specification.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Optimizing Workflow Performance by Elucidating Semantic Data Flow
SessionResearch Posters Display
DescriptionDistributed scientific workflows are becoming data-intensive, and the data movement through storage systems often causes bottleneck. Therefore, it is critical to understand data flow. Many scientific datasets incorporate domain semantics with formats like HDF and NetCDF, enhancing the interpretability and context of the data for analysis. We shed new insights on workflow bottlenecks by understanding how semantic data sets flow through storage. We unveil a fresh perspective with careful runtime measurement, recovering the mapping of domain semantics to low-level I/O operations, and effective visualization and analysis of semantic flows.




Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
The Many Facets of a Dynamic Graph Processing System
SessionResearch Posters Display
DescriptionGraphs are used to model real-world systems that often evolve over time. We have developed a streaming graph framework which, while ingesting an unbounded stream of events mirroring a graph's evolution, dynamically updates the solution to a user query, and is able to offer, on-demand and with low latency, the solution to the query. Integral to our framework is that graph topology changes and algorithmic messages are processed concurrently, asynchronously, and autonomously (i.e., without shared state). This poster uses graph coloring as a challenge problem to highlight two advantages of our framework beyond those showcased by past work (i.e., low result latency, high sustained ingestion throughput, and scalability). These additional advantages are: (i) the ability to efficiently leverage the "free" computational resources available when the rate of incoming topology events is below the maximum sustainable throughput, and (ii) the ability to produce "stable" solutions to queries as the graph evolves.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
sys-sage: A Fresh View on Dynamic Topologies and Attributes of HPC Systems
SessionResearch Posters Display
DescriptionHPC systems are getting ever more powerful, but this comes at the price of increasing system complexity. In order to use HPC systems efficiently, one has to be aware of their architectural details, in particular details of their hardware topology, which is increasingly affected by dynamic runtime settings.
sys-sage is a novel approach providing an infrastructure for storage, correlation, and provision of HW-related system information. It uses information from various well-known sources as well as use-case-specific solutions, and correlates the particular pieces together to provide a full view of a system. The novelty of our approach lies in the ability to capture dynamic environments as well as systems’ complexities, and in enabling greater flexibility in its usage.
sys-sage is publicly available and can be used by many applications. It integrates widely used approaches, such as hwloc or dynamic counter information, and offers user-integration of all other user-specific data sources.
sys-sage is a novel approach providing an infrastructure for storage, correlation, and provision of HW-related system information. It uses information from various well-known sources as well as use-case-specific solutions, and correlates the particular pieces together to provide a full view of a system. The novelty of our approach lies in the ability to capture dynamic environments as well as systems’ complexities, and in enabling greater flexibility in its usage.
sys-sage is publicly available and can be used by many applications. It integrates widely used approaches, such as hwloc or dynamic counter information, and offers user-integration of all other user-specific data sources.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Simulating Application Agnostic Process Assignment for Graph Workloads on Dragonfly and Fat Tree Topologies
SessionResearch Posters Display
DescriptionDistributed-memory graph applications are dominated by communication and synchronization overheads. For such applications, the communication pattern comprises of variable-sized data exchanges between process neighbors in a process graph topology, which unlike process grid for rectangular problems is difficult to optimize for enhancing the locality in a sustainable fashion.
Process assignment or remapping can improve the communication performance, however, existing solutions mostly caters to Cartesian process topologies and not the graph topology. In this work, we propose application and topology agnostic process remapping strategies for graph applications. For two communication intensive distributed-memory graph applications (graph clustering and triangle counting), we demonstrate about 30% improvements in the overall execution times through various remapping methodologies via SST-based packet-level simulations on Dragonfly and Fat Tree based network topologies.
Process assignment or remapping can improve the communication performance, however, existing solutions mostly caters to Cartesian process topologies and not the graph topology. In this work, we propose application and topology agnostic process remapping strategies for graph applications. For two communication intensive distributed-memory graph applications (graph clustering and triangle counting), we demonstrate about 30% improvements in the overall execution times through various remapping methodologies via SST-based packet-level simulations on Dragonfly and Fat Tree based network topologies.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Geospatial Filter and Refine Computations on NVIDIA Bluefield Data Processing Units (DPU)
SessionResearch Posters Display
DescriptionIn this poster, we will show how to leverage Nvidia's Bluefield Data Processing Unit (DPU) in geospatial systems. Existing work in literature has explored DPUs in the context of machine learning, compression and MPI acceleration. We show our designs on how to integrate DPUs into existing high performance geospatial systems like MPI-GIS. The workflow of a typical spatial computing workload consists of two phases - filter and refine. First we used DPU as a target to offload spatial computations from the host CPU. We show the performance improvements due to offload. Next we used DPU for network I/O processing. In network I/O case, the query data first comes to DPU for filtering and then the query goes to CPU for refinement. DPU-based filter and refine system can be useful in other domains like Physics where an FPGA is used to perform the filter to handle Big Data.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

NeoRodinia: Evaluation of High-Level Parallel Programming Models and Compiler Transformation for GPU Offloading
SessionResearch Posters Display
DescriptionNeoRodinia is a comprehensive benchmark suite developed from Rodinia, containing 23 real-world applications and 5 microbenchmarks. It addresses the limitations of Rodinia by optimizing OpenMP GPU offloading programs and introducing OpenACC variants. The evaluation involves thorough performance assessments on various hardware architectures and compilers, measuring execution time and memory usage. These evaluations offer valuable insights into parallel programming models and compiler choices, guiding optimization efforts and helping developers, especially beginners to make informed decisions.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Integrating TEZIP into LibPressio: A Case Study of Integrating a Dynamic Application into a Static C Environment
SessionResearch Posters Display
DescriptionLCLS-II at SLAC, SNS at Oak Ridge Laboratory, and other instruments use software written in C and C++, producing huge volumes of time evolving data at high rate. Data compression can decrease the volume of data we need to move and store. TEZIP is a neural network (NN) based compressor designed for high-quality compression of time-evolving data. However, TEZIP is written in Python and is not easily usable from or ported to C++. In this work, we develop new components in LibPressio that allow us to integrate with TEZIP and other external compressors efficiently and evaluate them with a systematic approach. We find that TEZIP’s compression ratio (Error Bound 1e-06) for Hurricane Isabel is 128, which is 2.4 times greater than the leading SZ3’s, 52.8. Our basic integration of TEZIP into Libpressio sets a precedent for the integration of non C/C++ compressors into LibPressio.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Characterizing GPU Effectiveness on NRP for IceCube fp32 Compute
SessionResearch Posters Display
DescriptionThe IceCube Neutrino Observatory is a cubic kilometer neutrino telescope located at the geographic South Pole. Understanding detector systematic effects is a continuous process. This requires the Monte Carlo simulation to be updated periodically to quantify potential changes and improvements in science results with more detailed modelling of the systematic effects. IceCube’s largest systematic effect comes from the optical properties of the ice the detector is embedded in. Over the last few years there have been considerable improvements in the understanding of the ice, which require a significant processing campaign to update the simulation. In winter 2023, the NRP project offered to provide the needed GPU compute to IceCube in support of this activity. Given the mostly uniform nature of such a simulation campaign, we thus have enough statistics to properly characterize the relative performance of the dozen GPU models present in the NRP in the context of IceCube.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Exploring Userspace Memory Mapping for RDMA-Enabled Network-Attached Memory
SessionResearch Posters Display
DescriptionMemory-bound applications like graph processing applications often require large memory capacity beyond a single node. Current HPC systems over-provision compute and memory resources to meet requirements of diverse workloads. In this work, we explore using network-attached memory for disaggregating memory from compute nodes to satisfy the demand of memory-intensive workloads. We provide a library that enables applications to access network-attached memory as if in its main memory, and exposes critical controls to userspace, including concurrency level and page-level data compression. Our preliminary results show that the flexibility of tuning concurrency and compression is important for improving performance and reducing data movement. Also, our results on 12 scientific data sets indicate that DPU compression offloading could significantly speed up compression and is important for future optimizations.



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Minimizing Data Movement Using Distant Futures
SessionResearch Posters Display
DescriptionScientific workflows execute a series of tasks where each task may consume data as an input and produce data as an output. Within these workflows, tasks often produce intermediate results that may serve as inputs to subsequent tasks within the workflow. These results can vary in size and may need to be transported to another worker node. Data movement can become the primary bottleneck for many scientific workflows thus minimizing the cost of data movement can provide a significant performance benefit for a given workflow. Distant futures enable transfers between worker nodes, eliminating the need for intermediate results to pass through a centralized manager for future tasks invocations. Additionally, asynchronous transfers enable increased concurrency by preventing the blocking of task invocations. This poster shows the performance benefit received from the implementation of distant futures within a workflow that produces numerous intermediate results.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Why Wait!? Hades: An Active, Content-Aware System for Precalculating Derived Quantities
SessionResearch Posters Display
DescriptionModern scientific applications produce vast amounts of data, typically stored in monolithic files on parallel file systems (PFS). Analyzing these large files often results in inefficiency due to I/O stalls. To mitigate these stalls, certain data can be pre-computed during the production phase and queried during analysis. However, this solution demands added storage capacity and an astute use of storage hierarchies. In this context, we introduce Hades, an I/O engine seamlessly integrated with the Adios2 framework. Hades offers hierarchical buffering, which enables smart data placement and prefetching across the spectrum of I/O devices. Additionally, it is adept at computing basic derived quantities required by I/O applications, such as the global and local min/max values. A notable feature of Hades is its memory-first metadata management strategy, which is designed for querying derived data, significantly enhancing system performance.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Exploring Green Cryptographic Hashing Algorithms for Eco-Friendly Blockchains
SessionResearch Posters Display
DescriptionCryptographic hash functions are fundamental for ensuring data security and integrity in all consensus algorithms in blockchains. While SHA256 has been widely used in many blockchain implementations, its throughput and efficiency has led the rise of a modern lightweight and speed superior implementation BLAKE3. We compared and contrasted SHA256 and BLAKE3 with a focus on blockchain workloads with small inputs and outputs. We explored different compilers and optimizations, different ways to parallelize using multi-threading and multi-processing, as well as different size systems from small Raspberry Pi 4 to a modern AMD Epyc server. We found that BLAKE3 is superior from a performance perspective. To showcase its strengths, we integrated BLAKE3 into a basic Proof-of-Space implementation that used advanced data index and search, and compared our results to the Chia blockchain plotting mechanism. Our approach offers one to two orders of magnitude higher hash generation and storage rates.
Authors

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Automating HPC Model Selection on Edge Devices
SessionResearch Posters Display
DescriptionThe increasing demand for processing power on resource-constrained edge devices necessitate efficient techniques for optimizing High Performance Computing (HPC) applications. We propose HPEE (HPC Parameter Exploration on Edge), a novel approach that formulates the parameter search space problem as a pure exploration multi-armed bandit (MAB) technique. By efficiently exploring the search space using the MAB framework, we achieve significant performance improvements, while respecting the limited computational resources of edge devices. Experimental results, based on HPC application, demonstrate the effectiveness of our approach in optimizing parameter search on edge devices, offering a promising solution for enhancing HPC performance in resource-constrained environments.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Graph Based Anomaly Detection in Chimbuko: Feasible or Fallible?
SessionResearch Posters Display
DescriptionPerformance anomaly detection can aid in discovering algorithmic inefficiencies or hardware issues in an application’s environment. The Chimbuko framework monitors large-scale workflow applications in real-time and identifies function executions which deviate from accumulated statistics (performance anomalies). Performance anomalies across runs correlate with variation in execution times of an application; quicker resolution of performance anomalies caused by hardware issues improves cluster performance. Anomalous and normal executions are stored as events in Chimbuko. In this study, we investigate the applicability of graph-based deep learning methods for anomaly classification. We hypothesize that transforming data into a graph will allow correlations to be modeled, thus allowing graph-based methods to learn embeddings that can improve the effectiveness of downstream anomaly classification tasks. Our evaluations demonstrate that the graph-based methods yield up to 95% accuracy and outperform a state-of-the-art gradient-based method. Moreover, we provide an explanation of the classification model’s decision-making process through explainable AI techniques.



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Investigating Anomalies in Compute Clusters: An Unsupervised Learning Approach
SessionResearch Posters Display
DescriptionAs compute clusters used for running batch jobs continue to grow in scale and complexity, the frequency of anomalies significantly increases. Timely detection of anomalous events has become vital to maintain system efficiency and availability. Our study presents an attention-based graph neural network (GNN) to detect anomalies in clusters at the compute node level and provide detailed root cause analysis to pinpoint issues. Evaluating on real-world datasets, attention-based GNN shows its ability to accurately detect and localize anomalies.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Temporal Classification of Allocations for Reduced Memory Usage
SessionResearch Posters Display
DescriptionUmpire, a data and memory management API created at LLNL, provides memory pools which enable less expensive ways to allocate large amounts of memory in HPC environments. Memory pools commonly contain both allocations that persist for only a portion of the program (temporary) and those that persist for the entire program (permanent). However, too much of a mix of both allocation types can lead to pool fragmentation and cause the pool to perform poorly. Umpire created a tool that uses a machine learning model to perform temporal classifications and categorize allocations as either temporary or permanent. We conducted experiments using trace files from two LLNL applications to study how much memory can be saved when those allocations are separated into distinct pools. We found that our ML tool accurately classifies memory allocations and that separating these allocation types into distinct pools reduces overall memory usage significantly (up to 29.5%).
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Toward Inductive Synthesis of Compiler Heuristics: A Case Study with Register Allocation
SessionResearch Posters Display
DescriptionThere have been significant advances in machine learning-driven performance modeling in recent years. One key limitation of such approaches is that their success depends, to a large degree, on the formulation of the outcome or objective, which is typically done by human experts. In this paper, we propose a novel approach of automatically generating new optimization heuristics using inductive program synthesis. To explore the feasibility of this approach, we investigated the graph-coloring register allocation heuristic used in the state-of-the-art compilers today. In particular, we focused on the task of live range splitting. The results show that when using a Genetic Algorithm, we can obtain splitting heuristics that are within 10% of the optimal split after 202 generations.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
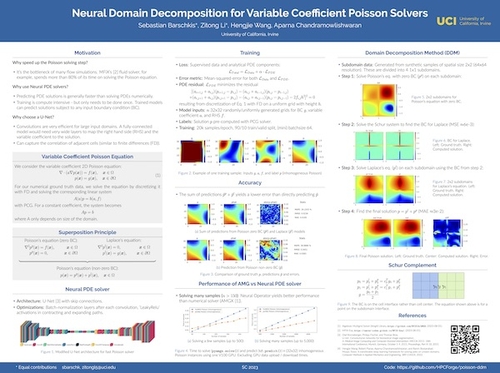
Neural Domain Decomposition for Variable Coefficient Poisson Solvers
SessionResearch Posters Display
DescriptionThe computational bottleneck in many fluid simulations arises from solving the variable coefficient Poisson equation. To tackle this challenge, we propose a novel neural domain decomposition algorithm to accelerate its solution. Our approach hinges on two key ideas: first, using neural PDE solvers to approximate the solutions within subdomains, and second, ensuring continuity across subdomain boundaries by solving a Schur complement system derived from the cell-centered discretized Poisson equation. A distinct advantage of our approach lies in generating a large dataset consisting only of small-scale problems to train the subdomain solver. This trained model can subsequently be applied to problems with large and complex geometries. Moreover, by batching the independent subdomain solves, we achieve high GPU utilization with neural solvers compared to state-of-the-art numerical methods. In contrast to neural domain decomposition algorithms that rely on Schwarz overlapping methods, our optimization-based approach, coupled with neural PDE solvers, improves accuracy and performance.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Software Development Case Study: The Acceleration of a Distributed Application Using GPUs
SessionResearch Posters Display
DescriptionWe present a practical approach for the acceleration of an industrial and scientific application using graphics processing units (GPUs). Our original application is a computational stratigraphy codebase that couples fluid flow and sediment deposition submodels. The application uses domain decomposition and a halo exchange to split the workload among multiple workers in a distributed system. Our methodology abstracts and conserves the host data structures while re-writing computational elements in the GPU programming language CUDA. Utilizing high performance GPU machines in the Azure cloud, we show a minimum 90x speedup compared to a high-end CPU based cluster. In this poster, we give a brief description of the original algorithm, followed by a discussion of required software changes and additions. Although this case study focuses on a specific example, we hope this approach inspires similar efforts in other applications.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Delivering Digital Skills Across the Digital Divide: Creating an Accessible On-Demand Self-Paced HPC Virtual Training Lab
SessionResearch Posters Display
DescriptionThe training of new and existing HPC practitioners is recognized as a priority in the HPC community. Traditionally, delivering HPC System Administrator training has been through physical face-to-face workshops, using cloud-based services or remote hardware to provide compute resources to emulate an HPC system. There are several challenges associated with this approach, including class size limits, available compute resources, and disrupting work hours to attend training. By following lessons learned from MOOC methodology on developing HPC Training we have produced a reproducible, accessible, self-paced HPC virtual training lab that emulates a basic 3-node compute cluster on a trainee’s local machine without the need for any high-end computing resources or cloud infrastructure.
Our poster will provide an overview of the project, inter alia the delivery platforms, components and features of the lab, lessons learned and future improvements, as well as future plans for extended HPC training modules following this delivery format.
Our poster will provide an overview of the project, inter alia the delivery platforms, components and features of the lab, lessons learned and future improvements, as well as future plans for extended HPC training modules following this delivery format.
Authors



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

EE-HPC – A Framework for Energy Efficient HPC System Operation
SessionResearch Posters Display
DescriptionThe energy consumption of HPC data centers is a decisive factor in the procurement and operation of the systems. EE-HPC achieves a more efficient energy use of HPC systems by targeted job-specific control and optimization of the hardware. The project started end of 2022 and builds on the existing stable software components ClusterCockpit and LIKWID. It provides a simple, robust, secure and scalable monitoring and energy control solution for hybrid HPC clusters. The job-specific performance and monitoring framework ClusterCockpit is already used in production at several large HPC computing centers. The energy manager and node controller is implemented in a Python based prototype and will be ported to Golang and integrated in ClusterCockpit. The framework will be evaluated with a set of relevant HPC applications from molecular dynamics, engineering, and climate research.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Real-Time Change Point Detection in Molecular Dynamics Streaming Data
SessionResearch Posters Display
DescriptionThe uniform sampling of molecular dynamics (MD) simulations may not accurately capture crucial scientific events. Deep learning approaches are being developed to detect these events within streaming data but can take significant resources on large datasets (PB+). To address these limitations, we propose a solution based on streaming manifold learning, specifically the Kernel CUSUM (KCUSUM) algorithm. By leveraging KCUSUM, we can overcome the limitations of uniform sampling in MD simulations, as it compares incoming data with samples from a reference distribution. It utilizes a statistic derived from the Maximum Mean Discrepancy (MMD) non-parametric testing framework. This algorithm has been tested in various use cases, demonstrating its ability to significantly reduce data rates without missing important scientific events.
Authors



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

A High-Performance I/O Framework for Accelerating DNN Model Updates Within Deep Learning Workflow
SessionResearch Posters Display
DescriptionIn traditional deep learning workflows, AI applications (producers) train DNN models offline using fixed datasets, while inference serving systems (consumers) load the trained models for offering real-time inference queries. In practice, AI applications often operate in a dynamic environment where data is constantly changing. Compared to offline learning, Continuous learning frequently (re)-trains models to adapt to the ever-changing data. This demands regular deployment of the DNN models, increasing the model update frequency between producers and consumers. Typically, producers and consumers are connected via model repositories like PFS, which may result in high model update latency due to I/O bottleneck of PFS. To address this, our work introduces a high-performance I/O framework that speeds up model updates between producers and consumers. It employs a cache-aware model handler to minimize the latency and an intelligent performance predictor to maintain a balance between training and inference performance.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
HPC Accelerated Generative Deep Learning Approach for Creating Digital Twins of Climate Models
SessionResearch Posters Display
DescriptionClimate models cannot perfectly represent the complex climate system, but by running them multiple times with small variations in input parameters, it's possible to estimate uncertainties and explore different climate scenarios. Generating these ensembles demands significant computational resources and time, which can be crucial for risk assessments and decision-making. This study utilizes generative adversarial networks (GANs) and deep diffusion models (DDMs) to produce low-resolution ensemble runs trained on data provided by climate model simulations with low computational expense. Additionally, convolutional neural networks (CNNs) are employed for downscaling as well as parallelization techniques to enhance performance and reduce computation time. This approach allows for time-efficient exploration of high-resolution ensemble members, facilitating climate modeling investigations that were previously challenging due to resource constraints.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

A Portable Software Environment for Ultrahigh-Resolution ELM Development on GPUs
SessionResearch Posters Display
DescriptionA software tool, called SPEL, has been developed to port and optimize and the ultrahigh-resolution ELM (uELM) code onto GPUs within a functional unit test framework. To promote the widespread adoption of this approach for community-based uELM development, this poster presents a portable software environment that enables efficient development of the uELM code on GPUs. The standalone software environment, which utilizes Docker, contains all the necessary code, libraries, and system software required for uELM development using SPEL. The process involved in this study includes identifying a Docker image that supports GPU, configuring and simulating ELM at the site level, capturing reference solutions, testing uELM functional units, and generating and optimizing code that is compatible with GPUs. The effectiveness of this methodology is demonstrated through a case study.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
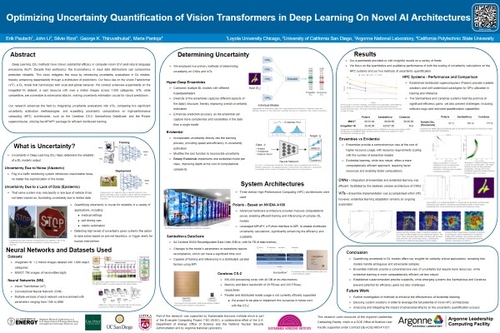
Optimizing Uncertainty Quantification of Vision Transformers in Deep Learning on Novel AI Architectures
SessionResearch Posters Display
DescriptionDeep Learning (DL) methods have shown substantial efficacy in computer vision (CV) and natural language processing (NLP). Despite their proficiency, the inconsistency in input data distributions can compromise prediction reliability. This study mitigates this issue by introducing uncertainty evaluations in DL models, thereby enhancing dependability through a distribution of predictions. Our focus lies on the Vision Transformer (ViT), a DL model that harmonizes both local and global behavior. We conduct extensive experiments on the ImageNet-1K dataset, a vast resource with over a million images across 1,000 categories. ViTs, while competitive, are vulnerable to adversarial attacks, making uncertainty estimation crucial for robust predictions.
Our research advances the field by integrating uncertainty evaluations into ViTs, comparing two significant uncertainty estimation methodologies, and expediting uncertainty computations on high-performance computing (HPC) architectures, such as the Cerebras CS-2, SambaNova DataScale, and the Polaris supercomputer, utilizing the MPI4PY package for efficient distributed training.
Our research advances the field by integrating uncertainty evaluations into ViTs, comparing two significant uncertainty estimation methodologies, and expediting uncertainty computations on high-performance computing (HPC) architectures, such as the Cerebras CS-2, SambaNova DataScale, and the Polaris supercomputer, utilizing the MPI4PY package for efficient distributed training.





Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
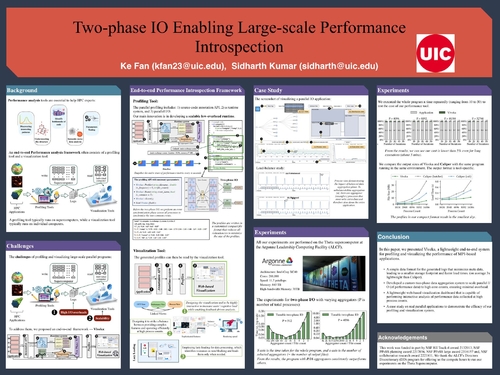
Two-Phase IO Enabling Large-Scale Performance Introspection
SessionResearch Posters Display
DescriptionNumerous sophisticated profiling and visualization tools have been developed to enable programmers to expose semantic information from their application components. However, effective and interactive exploration of the profiles of large-scale parallel programs remains a challenge due to the high I/O overheads of profiles and the difficulties in scaling downstream visualization tools. In this poster, we present a full-stack approach to a performance introspection framework that tackles key challenges in profiling and visualizing performance data at scale. Our novelty lies in a scalable and compact data model and a two-phase I/O system, which instill scalability into the profiler making it low overhead-- even at high process counts (< 5%). We then build a web-based, visual-analytic dashboard with linked views. Our profiling and visualization tools are both lightweight and easy-to-use, which strikes a balance between providing sophisticated features and operating quickly and efficiently at high process counts.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
Performance Measurement, Modeling, and Tools
TP
XO/EX
Archive
view
Hide Details

Characterizing One-/Two-Sided Designs in OpenSHMEM Collectives
SessionResearch Posters Display
DescriptionOpenSHMEM is a widely used Partitioned Global Address Space (PGAS) programming model in the HPC community. The latest OpenSHMEM Specification v1.5 introduced the team concept and team-based collective communication that are similar to the communicator and collective communication in the Message Passing Interface (MPI) programming model. However, the typical design of OpenSHMEM collectives relies on one-sided communication such as PUT and Get to move the data, which is different from two-sided communication in MPI collectives. In this work, we compare OpenSHMEM collective designs using native one-sided communication and MPI-based two-sided communication on an HPC cluster. We characterize two aspects (i.e., synchronization and collective algorithms) that can influence the performance of these two different designs and use benchmarks to show the performance differences. Through our evaluation, we find that the MPI-based design is faster than the one-sided design at most times, while the one-sided design can perform faster in certain cases.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Modeling Parallel Programs Using Large Language Models
SessionResearch Posters Display
DescriptionIn the past year a large number of large language model (LLM) based tools for software development have been released. These tools have the capability to assist developers with many of the difficulties that arise from the ever-growing complexity in the software stack. As we enter the exascale era, with a diverse set of emerging hardware and programming paradigms, developing, optimizing, and maintaining parallel software is becoming burdensome for developers. While LLM-based coding tools have been instrumental in revolutionizing software development, mainstream models are not designed, trained, or tested on High Performance Computing (HPC) problems. We present a LLM fine-tuned on HPC data and demonstrate its effectiveness in HPC code generation, OpenMP parallelization, and performance modeling.



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
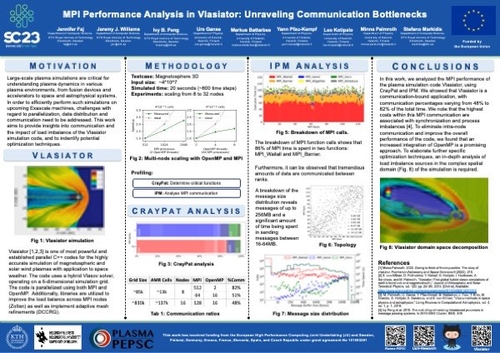
MPI Performance Analysis in Vlasiator: Unraveling Communication Bottlenecks
SessionResearch Posters Display
DescriptionVlasiator is a popular and powerful massively parallel code for accurate magnetospheric and solar wind plasma simulations. This work provides an in-depth analysis of Vlasiator, focusing on MPI performance using the Integrated Performance Monitoring (IPM) tool. We show that MPI non-blocking point-to-point communication accounts for most of the communication time. The communication topology shows a large number of MPI messages exchanging data in a six-dimensional grid. We also show that relatively large messages are used in MPI communication, reaching up to 256MB. As a communication-bound application, we found that using OpenMP in Vlasiator is critical for eliminating intra-node communication. Our results provide important insights for optimizing Vlasiator for the upcoming Exascale machines.
Authors


Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Exploring Julia as a Unifying End-to-End Workflow Language for HPC on Frontier
SessionResearch Posters Display
DescriptionWe evaluate the use of Julia as a single language and ecosystem paradigm powered by LLVM for the development of high-performance computing (HPC) workflow components. A Gray-Scott 2-variable diffusion-reaction application using a memory-bound 7-point stencil kernel is run on Frontier, the first exascale supercomputer. We evaluate the feasibility, performance, scaling, and trade-offs of (i) the computational kernel on AMD's MI250x GPUs, (ii) weak scaling up to 4,096 MPI processes/GPUs or 512 nodes, (iii) parallel I/O write using the ADIOS2 library bindings, and (iv) Jupyter Notebooks for interactive data analysis.
We will discuss our results which show that although Julia generates a reasonable LLVM-IR kernel, there is nearly a 50% performance difference with native AMD HIP stencil codes on GPU. We observed near-zero overhead when using MPI and parallel I/O bindings to system-wide installed implementations. Consequently, Julia emerges as a compelling high-performance and high-productivity workflow composition strategy as measured on Frontier.
We will discuss our results which show that although Julia generates a reasonable LLVM-IR kernel, there is nearly a 50% performance difference with native AMD HIP stencil codes on GPU. We observed near-zero overhead when using MPI and parallel I/O bindings to system-wide installed implementations. Consequently, Julia emerges as a compelling high-performance and high-productivity workflow composition strategy as measured on Frontier.
Authors





Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Exploring the Impacts of Multiple I/O Metrics in Identifying I/O Bottlenecks
SessionResearch Posters Display
DescriptionHPC systems, driven by the rise of workloads with significant data requirements, face challenges in I/O performance. To address this, a thorough I/O analysis is crucial to identify potential bottlenecks. However, the multitude of metrics makes it difficult to pinpoint the causes of low I/O performance. In this work, we analyze three scientific workloads using three widely accepted I/O metrics. We demonstrate that different metrics uncover different I/O bottlenecks, highlighting the importance of considering multiple metrics for comprehensive I/O analysis.



Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
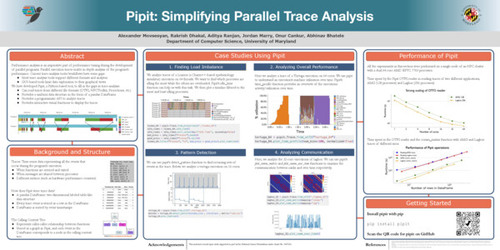
Pipit: Simplifying Analysis of Parallel Execution Traces
SessionResearch Posters Display
DescriptionPer-process per-thread traces enable in-depth analysis of parallel program execution to identify various kinds of performance issues. Often times, trace collection tools provide a graphical tool to analyze the trace output. However, these GUI-based tools only support specific file formats, are difficult to scale when the data is large, limit data exploration to the implemented graphical views, and do not support automated comparisons of two or more datasets. In this poster, we present a pandas-based Python library, Pipit, which can read traces in different file formats (OTF2, HPCToolkit, Projections, Nsight, etc.) and provide a uniform data structure in the form of a pandas DataFrame. Pipit provides operations to aggregate, filter, and transform the events in a trace to present the data in different ways. We also provide several functions to quickly identify performance issues in parallel executions.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
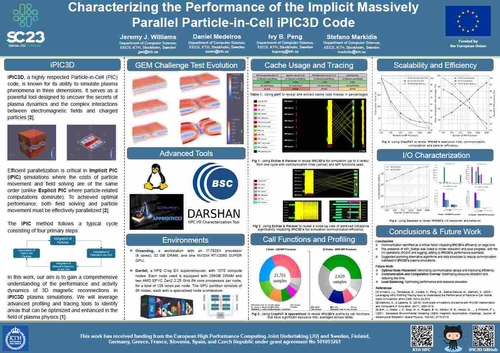
Characterizing the Performance of the Implicit Massively Parallel Particle-in-Cell iPIC3D Code
SessionResearch Posters Display
DescriptionOptimizing iPIC3D, an implicit Particle-in-Cell (PIC) code, for large-scale 3D plasma simulations is crucial for space and astrophysical applications. This work focuses on characterizing iPIC3D’s communication efficiency through strategic measures like optimal node placement, communication and computation overlap, and load balancing. Profiling and tracing tools are employed to analyze iPIC3D’s communication efficiency and provide practical recommendations. Implementing optimized communication protocols addresses the Geospace Environmental Modeling (GEM) magnetic reconnection challenges in plasma physics with more precise simulations. This approach captures the complexities of 3D plasma simulations, particularly in magnetic reconnection, advancing space and astrophysical research.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Early Experience in Characterizing Training Large Language Models on Modern HPC Clusters
SessionResearch Posters Display
DescriptionIn the realm of natural language processing, Large Language Models (LLMs) have emerged as powerful tools for tasks such as language translation, text generation, and sentiment analysis. However, the immense parameter size and complexity of LLMs present significant challenges. This work delves into the exploration and characterization of high-performance interconnects in the distributed training of various LLMs. Our findings reveal that high-performance network protocols, notably RDMA, significantly outperform other protocols like IPoIB and TCP/IP in training performance, offering improvements by factors of 2.51x and 4.79x respectively. Additionally, we observe that LLMs with larger parameters tend to demand higher interconnect utilization. Despite these findings, our study suggests potential for further optimization in overall interconnect utilization. This research contributes to a deeper understanding of the performance characteristics of LLMs over high-speed interconnects, paving the way for more efficient training methodologies.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
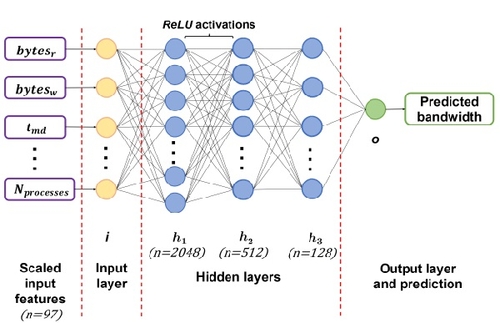
Transfer Learning Workflow for High-Quality I/O Bandwidth Prediction with Limited Data
SessionResearch Posters Display
DescriptionThe I/O performance prediction is challenging due to multiple intertwined variables inside a cluster. This situation makes I/O performance prediction a strong candidate for using machine learning because of the complex variables involved. However, making a high-quality prediction requires a large amount of equivalent-quality data, and collecting it is a big challenge for most data centers.
In this project, we explore transfer learning to predict the I/O performance by utilizing the publicly available I/O performance data in Darshan logs from the NCSA's Blue Waters supercomputer. We devise a workflow to train a neural network model as a base to predict the POSIX I/O bandwidth of other clusters (CLAIX18 and Theta). With less than 1% of the data needed to build the base model, our experiment shows that our transfer learning workflow can predict the I/O bandwidth of another system with a mean absolute error better or equivalent to the state-of-the-art.
In this project, we explore transfer learning to predict the I/O performance by utilizing the publicly available I/O performance data in Darshan logs from the NCSA's Blue Waters supercomputer. We devise a workflow to train a neural network model as a base to predict the POSIX I/O bandwidth of other clusters (CLAIX18 and Theta). With less than 1% of the data needed to build the base model, our experiment shows that our transfer learning workflow can predict the I/O bandwidth of another system with a mean absolute error better or equivalent to the state-of-the-art.




Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

DFToy: A New Proxy App for DFT Calculations
SessionResearch Posters Display
DescriptionDensity functional theory based codes are significant users of HPC resources, often ranking among the top users of core hours on these systems. However, despite their popularity and resource usage, they are not very well optimised for current HPC architectures - and are not easily adapted. We present DFToy, a new proxy-app for DFT codes that is accessible, easy to understand and FOSS. DFToy's accessibility makes it an excellent platform for benchmarking, experimentation and development - allowing developers to research novel algorithms for DFT codes.
We will show DFToy's use and capabilities in its current state, compare its behavior to a state-of-the-art DFT code, and discuss where we will take the code going forward - including the development of a self-tuning parallel model.
We will show DFToy's use and capabilities in its current state, compare its behavior to a state-of-the-art DFT code, and discuss where we will take the code going forward - including the development of a self-tuning parallel model.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Hybrid CPU-GPU Implementation of Edge-Connected Jaccard Similarity in Graph Datasets
SessionResearch Posters Display
DescriptionTypical GPU programs consist of four steps: (1) data preparation, (2) host CPU-to-GPU data transfers, (3) execution of one or more GPU kernels, and (4) transfer of results back to CPU. While the kernel is running on the GPU, the CPU cores often remain idle, waiting on the GPU to finish kernel execution.
In recent years, several frameworks have been presented that perform automated distribution of workload to both CPU and GPU. While the aforementioned frameworks offer techniques for CPU+GPU workload distribution for regular applications, identifying a performant CPU+GPU workload distribution for irregular applications remains a difficult problem due to workload imbalance and irregular memory access patterns.
This work evaluates a hybrid CPU+GPU implementation of an irregular workload -- graph link prediction using the Jaccard similarity. For the graphs that benefit the most from our hybrid CPU-GPU approach, our implementation delivers a 16.4-28.4% improvement over the state-of-the-art Jaccard similarity implementation.
In recent years, several frameworks have been presented that perform automated distribution of workload to both CPU and GPU. While the aforementioned frameworks offer techniques for CPU+GPU workload distribution for regular applications, identifying a performant CPU+GPU workload distribution for irregular applications remains a difficult problem due to workload imbalance and irregular memory access patterns.
This work evaluates a hybrid CPU+GPU implementation of an irregular workload -- graph link prediction using the Jaccard similarity. For the graphs that benefit the most from our hybrid CPU-GPU approach, our implementation delivers a 16.4-28.4% improvement over the state-of-the-art Jaccard similarity implementation.


Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
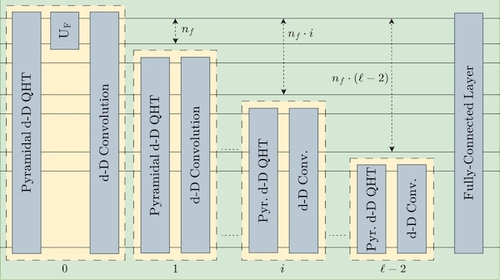
Preserving Data Locality in Multidimensional Variational Quantum Classification
SessionResearch Posters Display
DescriptionIn classical machine learning, the convolution operation is leveraged in the eponymous class of convolutional neural networks (CNNs) capturing the spatial and/or temporal locality of multidimensional input features. Preserving data locality allows CNN models to reduce the number of training parameters, and hence their training time, while achieving high classification accuracy. However, contemporary methods of quantum machine learning do not possess effective methods for exploiting data locality, due to the lack of a generalized and parameterizable implementation of quantum convolution. In this work, we propose variational quantum classification techniques that leverage a novel multidimensional quantum convolution operation with arbitrary filtering and unity stride. We provide the quantum circuits for our techniques alongside corresponding theoretical analysis. We also experimentally demonstrate the advantage of our method in comparison with existing quantum and classical techniques for image classification in staple multidimensional datasets using state-of-the-art quantum simulations.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
Artificial Intelligence/Machine Learning
Post-Moore Computing
Quantum Computing
TP
XO/EX
Archive
view
Hide Details

SCALABLE – Scalable Lattice Boltzmann Leaps to Exascale
SessionResearch Posters Display
DescriptionThe SCALABLE project aims to enhance an industrial Lattice Boltzmann Method (LBM)-based computational fluid dynamics (CFD) solver for current and future extreme-scale architectures, while ensuring accessibility for end-users and developers. This is accomplished by transferring technology and knowledge between academic code waLBerla and industrial code LaBS.
This poster introduces both software packages and the technology transfer process, resulting in improved CPU and GPU performance and increased interest in energy efficiency.
LBM are trustworthy alternatives to conventional CFD, showing roughly an order of magnitude performance advantage over Navier-Stokes approaches in comparable scenarios.
SCALABLE unites waLBerla and LaBS developers to improve both solvers in terms of portability (targeting GPUs for example), energy efficiency scenarios and transferring techniques between the two to achieve high performance, scalability, and energy efficiency.
This poster introduces both software packages and the technology transfer process, resulting in improved CPU and GPU performance and increased interest in energy efficiency.
LBM are trustworthy alternatives to conventional CFD, showing roughly an order of magnitude performance advantage over Navier-Stokes approaches in comparable scenarios.
SCALABLE unites waLBerla and LaBS developers to improve both solvers in terms of portability (targeting GPUs for example), energy efficiency scenarios and transferring techniques between the two to achieve high performance, scalability, and energy efficiency.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Improving Memory Interfacing in HLS-Generated Accelerators with Custom Caches
SessionResearch Posters Display
DescriptionAccelerators based on reconfigurable devices are becoming popular for data analytics in high performance computing and cloud computing systems. However, designing these accelerators is a hard problem. High-Level Synthesis tools can help by generating RTL designs from high-level languages, but they tend to optimize the computational part of the kernel, often not considering data movement and memory accesses. For many applications, instead, memory operations take a significant part of the overall execution time and can be the actual bottleneck limiting performance, especially when accessing large, possibly remote, memories.
We propose an approach based on the generation and integration of highly-customizable accelerator caches in order to reduce the latency with which an HLS-generated accelerator accesses external memory through spatial and temporal locality. We integrate it in a state-of-the-art open-source HLS tool and show how our approach allows to easily explore tradeoffs between performance and resource utilization with minimal user effort required.
We propose an approach based on the generation and integration of highly-customizable accelerator caches in order to reduce the latency with which an HLS-generated accelerator accesses external memory through spatial and temporal locality. We integrate it in a state-of-the-art open-source HLS tool and show how our approach allows to easily explore tradeoffs between performance and resource utilization with minimal user effort required.
Authors

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
Programming Frameworks and System Software
TP
XO/EX
Archive
view
Hide Details
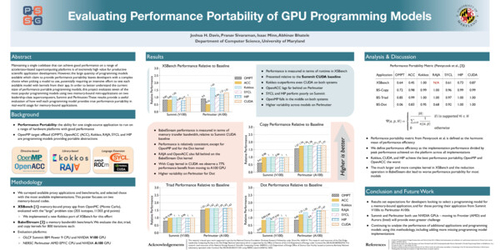
Evaluating Performance Portability of GPU Programming Models
SessionResearch Posters Display
DescriptionMaintaining a single codebase that can achieve good performance on a range of accelerator-based supercomputing platforms is of extremely high value for productive scientific application development. However, the large quantity of programming models available which claim to provide performance portability leaves developers with a complex choice when picking a model to use, potentially requiring an intensive effort to test each available model with kernels from their app. In order to better understand the current state of performance portable programming models, this project evaluates seven of the most popular programming models using two memory-bound mini-applications on two leadership-class supercomputers, Summit and Perlmutter. These results provide a useful evaluation of how well each programming model provides true performance portability in real-world usage for memory-bound applications.

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
Heterogeneous Computing
Performance Measurement, Modeling, and Tools
TP
XO/EX
Archive
view
Hide Details
The Impact of Process Topology on RMA Programming Models: A Study on NERSC Perlmutter
SessionResearch Posters Display
DescriptionRemote Memory Access (RMA) provides an alternate mechanism for data movement by separating communication with synchronization, exposing remote memory access features via one-sided communication semantics to a global address space. Performance of the most popular asynchronous RMA interfaces like MPI RMA and SHMEM has steadily improved over the past years due to better software/hardware support from the vendors and community-driven programming model standardization efforts.
Current RMA benchmarking efforts are mostly focused on investigating elementary data movement overheads between a process-pair within and across nodes, not considering a specific process topology. Distributed-memory applications on the other hand must deal with overlapped data distributions, which governs the underlying topology of the processes. We discuss the performance of SHMEM and MPI RMA (in comparison with MPI point-to-point) for grid and graph process topologies on NERSC Perlmutter supercomputer, demonstrating average and 99th percentile latencies.
Current RMA benchmarking efforts are mostly focused on investigating elementary data movement overheads between a process-pair within and across nodes, not considering a specific process topology. Distributed-memory applications on the other hand must deal with overlapped data distributions, which governs the underlying topology of the processes. We discuss the performance of SHMEM and MPI RMA (in comparison with MPI point-to-point) for grid and graph process topologies on NERSC Perlmutter supercomputer, demonstrating average and 99th percentile latencies.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Scalable Fine-Grained Gang Scheduling for HPC Systems with Unreliable Broadcast Synchronization Mechanisms
SessionResearch Posters Display
DescriptionThe demand for interactivity on HPC systems is increasing, primarily driven by new HPC users from the AI/ML research area. Traditional HPC users are accustomed to waiting for job execution on a batch scheduling system while new users prefer an interactive terminal such as Jupyter Notebook. To address these evolving requirements, enhancing interactivity is essential. Fine-grained gang scheduling is one potential solution for this problem. This poster presents a scalable inter-node synchronization mechanism that facilitates well-time-aligned synchronization message delivery through broadcast communication for fine-grained gang scheduling in HPC systems. The mechanism improved the application performance by 2.7 times in comparison to the existing implementation, when simultaneously executing two parallel applications on 128 computing nodes with a 500 ms time slice.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Sophisticated Tools for Performance Analysis and Auto-Tuning of Performance Portable Parallel Programming
SessionResearch Posters Display
DescriptionHPC Software must offer tool support for productive programming of scientific applications run on supercomputers using this HPC Software, especially for the sophisticated activities of performance analysis and auto-tuning. Given the emergence of performance portable programming libraries having abstractions for parallelism, new tool support offered by the HPC Software for such sophisticated activities is needed to handle these library abstractions over multiple backends. Addressing this will allow for software sustainability of performance portable libraries. Considering Kokkos, a representative C++-based Performance Portable Library, we focus on (1) a community-driven tool connector subset of the Kokkos Tools offer capability for such sophisticated activities along with (2) an associated tool infrastructure which includes common interfaces and utilities to enable such sophisticated tools. Showcasing this part of Kokkos Tools shows it is capable, lightweight, easy to use, and a viable alternative of such tools supporting specific low-level programming models.


Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

That's Right – The Same C++ STL Asynchronous Parallel Code Runs on CPUs and GPUs
SessionResearch Posters Display
DescriptionHigh-performance computing applications running on modern-day supercomputers frequently encounter performance and portability challenges especially if using multiple programming models, languages and compilers. In this work, we explore the proposed C++26 language standard model for asynchronous parallelism, called std::execution or stdexec, powered with stdpar, std::mdspan, among other C++23 features, to port and analyze multiple scientific HPC applications on CPUs and GPUs. These applications include sequence alignment codes from ADEPT and heat transfer from AMReX. Our experiments depict near-native performance for our ported implementations on NVIDIA A100 GPUs running on the Perlmutter supercomputer. We also study and analyze the data transfer traffic patterns and overheads between the host and device for stdpar and provide helpful insights in application performance. Finally, we discuss some challenges and limitations encountered while porting these apps to C++26 with stdexec, as well as their workarounds, until the stdexec is fully integrated and function in the NVHPC compilers.
Authors

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
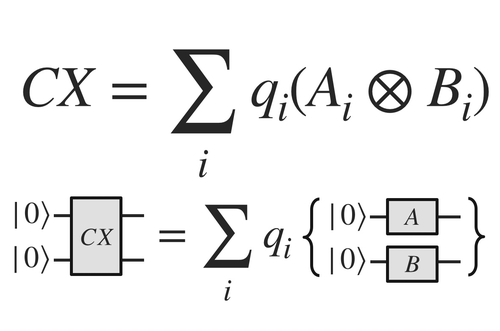
Simulating Larger Quantum Circuits with Circuit Cutting and Quantum Serverless
SessionResearch Posters Display
DescriptionQuantum computation is an emerging technology that promises to be able to solve certain tasks that are out of reach of classical machines alone. However, the limited number and quality of qubits poses a challenge for practical usage of near-term quantum computation. Circuit cutting is a technique to decrease the size of circuits at the cost of an additional sampling overhead. This can enable executing problems larger in size and with higher-quality outcomes than what available quantum hardware would otherwise support.
Here, we use the Circuit Knitting Toolbox (CKT) to demonstrate two applications of circuit cutting. To scale these workloads up to hundreds of qubits, we use Quantum Serverless – a new framework for distributing computationally expensive workloads in the cloud.
Here, we use the Circuit Knitting Toolbox (CKT) to demonstrate two applications of circuit cutting. To scale these workloads up to hundreds of qubits, we use Quantum Serverless – a new framework for distributing computationally expensive workloads in the cloud.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Quantum Task Offloading with the OpenMP API
SessionResearch Posters Display
DescriptionMost of the widely used quantum programming languages and libraries are not designed for the tightly coupled nature of hybrid quantum-classical algorithms, which run on quantum resources that are integrated on-premise with classical HPC infrastructure. We propose a programming model using the API provided by OpenMP to target quantum devices, which provides an easy-to-use and efficient interface for HPC applications to utilize quantum compute resources. We have implemented a variational quantum eigensolver using the programming model, which has been tested using a classical simulator. We are in the process of testing on the quantum resources hosted at LRZ.
Authors




Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details

Unleashing CGRA Potential for HPC
SessionResearch Posters Display
DescriptionThis poster highlights our previous and future design-space exploration effort to optimize our CGRA architecture for HPC, i.e., intra-CGRA interconnect optimization, FMA and transcendental operation on CGRA, programmable buffer, systolic-array style execution on CGRA, predication support, and FPGA based emulation on actual HPC environment.
Authors

Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Quantum Computing Case Study in Aerospace Field
SessionResearch Posters Display
DescriptionWith the demise of Moore’s empirical law, we cannot expect a dramatic improvement in computer performance in the future, but the need for supercomputer in JAXA for numerical simulation and data processing etc. continues to rise. Until now, general-purpose CPUs have been exclusively used, but there is an urgent need to seriously consider the use of dedicated computers and new architectures. One candidate is a quantum computer.
In order to study the feasibility of a quantum computer as a candidate for a new architecture, the Gate-Model Quantum Computer Study Group was established with JSS3: JAXA Supercomputer System generation 3 users as the main members, which examined the possibility of applying Gate-Model Quantum Computing technology to JAXA's technical problem areas, and will assist management in making mid to long-term decisions regarding computing resources.
The Group organized use cases created in workshops and gained insight into the effects of utilizing quantum technology.
In order to study the feasibility of a quantum computer as a candidate for a new architecture, the Gate-Model Quantum Computer Study Group was established with JSS3: JAXA Supercomputer System generation 3 users as the main members, which examined the possibility of applying Gate-Model Quantum Computing technology to JAXA's technical problem areas, and will assist management in making mid to long-term decisions regarding computing resources.
The Group organized use cases created in workshops and gained insight into the effects of utilizing quantum technology.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
Radium: Transparent Distributed Execution via Process Virtualization
SessionResearch Posters Display
DescriptionThe soaring demand for AI has led to a surge in specialized computation hardware, which poses challenges in sharing resources through conventional virtualization methods among end users. Moreover, the extensive data required by AI often cannot be conveniently co-located with the compute resources, resulting in costly and unsuitable migration attempts. To address these issues, Radium offers a userspace framework employing process virtualization, thread execution migration, and distributed shared memory. By leveraging Radium, an unmodified application binary operates in an encapsulated virtualized environment and its execution can be transparently distributed among nodes where resources are located. Radium enables resource aggregation with little performance penalty over high latency network connectivity. By choosing syscalls as the virtualization boundary, Radium supports novel hardware by nature without modifying existing infrastructure or applications.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Hide Details
QASM-to-HLS: A Framework for Accelerating Quantum Circuit Emulation on High-Performance Reconfigurable Computers
SessionResearch Posters Display
DescriptionHigh-performance reconfigurable computers (HPRCs) make use of Field-Programmable Gate Arrays (FPGAs) for efficient emulation of quantum algorithms. Generally, algorithm-specific architectures are implemented on the FPGAs, and there is very little flexibility. Moreover, mapping a quantum algorithm onto its equivalent FPGA emulation architecture is challenging. In this work, we present an automation framework for converting quantum algorithms/circuits to their equivalent FPGA emulation architectures. The framework processes quantum circuits represented in Quantum Assembly Language (QASM) and derives high-level descriptions of the hardware emulation architectures for High-Level Synthesis (HLS) on HPRCs. Experimental results show that the framework-generated architectures deployed on an HPRC perform faster than a state-of-the-art software simulator.
Event Type
Posters
Research Posters
TimeTuesday, 14 November 202310am - 5pm MST
LocationDEF Concourse
TP
XO/EX
Archive
view
Wednesday, 15 November 2023 3:30pm-3:39pm 505
Hide Details

A Formal Specification of Tensor Cores via Satisfiability Modulo Theories
DescriptionIn this work, we explore how to replicate the behavior of undocumented hardware units -- in this case, NVIDIA's Tensor Cores -- and reason about them.
While prior work has employed manual testing to identify hardware behavior, we show that SMT can be used to generate inputs that can discriminate between different hardware implementation choices. We argue that SMTLIB, the language specification for SMT solvers, is well suited for exposing hardware implementations.
Using our method, we create a formal specification of the tensor cores on NVIDIA's Volta architecture. We confirm many of the findings of previous studies on tensor cores, but also identify two discrepancies: we find that the hardware does not use IEEE-754 round-to-zero for accumulation and that the 5-term accumulator requires 3 extra bits for carry out since it does not normalize intermediate sums.
The work will be presented in person using the poster as a visual aid.
While prior work has employed manual testing to identify hardware behavior, we show that SMT can be used to generate inputs that can discriminate between different hardware implementation choices. We argue that SMTLIB, the language specification for SMT solvers, is well suited for exposing hardware implementations.
Using our method, we create a formal specification of the tensor cores on NVIDIA's Volta architecture. We confirm many of the findings of previous studies on tensor cores, but also identify two discrepancies: we find that the hardware does not use IEEE-754 round-to-zero for accumulation and that the 5-term accumulator requires 3 extra bits for carry out since it does not normalize intermediate sums.
The work will be presented in person using the poster as a visual aid.
Wednesday, 15 November 2023 3:39pm-3:48pm 505
Hide Details

Accelerating Collective Communications with Lossy Compression on GPU
DescriptionGPU-aware collective communication has become a major bottleneck for modern computing platforms as GPU computing power rapidly rises. To address this issue, traditional approaches integrate lossy compression directly into GPU-aware collectives, which still suffer from serious issues such as underutilized GPU devices and uncontrolled data distortion.
In this poster, we propose GPU-LCC, a general framework that designs and optimizes GPU-aware, compression-enabled collectives with well-controlled error propagation. To validate our framework, we evaluate the performance on up to 512 NVIDIA A100 GPUs with real-world applications and datasets. Experimental results demonstrate that our GPU-LCC-accelerated collective computation (Allreduce), can outperform NCCL as well as Cray MPI by up to 4.5X and 20.2X, respectively. Furthermore, our accuracy evaluation with an image-stacking application confirms the high reconstructed data quality of our accuracy-aware framework.
In this poster, we propose GPU-LCC, a general framework that designs and optimizes GPU-aware, compression-enabled collectives with well-controlled error propagation. To validate our framework, we evaluate the performance on up to 512 NVIDIA A100 GPUs with real-world applications and datasets. Experimental results demonstrate that our GPU-LCC-accelerated collective computation (Allreduce), can outperform NCCL as well as Cray MPI by up to 4.5X and 20.2X, respectively. Furthermore, our accuracy evaluation with an image-stacking application confirms the high reconstructed data quality of our accuracy-aware framework.
Wednesday, 15 November 2023 3:48pm-3:57pm 505
Hide Details
ROI Preservation in Streaming Lossy Compression
DescriptionToday’s state-of-the-art scientific high-performance computing (HPC) applications generate extensive data in diverse domains, placing a significant strain on data transfer and storage systems. Most compression algorithms are more computationally complex, requiring more processing power and time to compress and decompress data. However, these algorithms tend to achieve higher compression ratios resulting in smaller compressed data sizes. Real-time streaming applications demand high data throughput. Therefore, striking a right balance between compression efficiency and computational complexity is essential. This poster explores two key aspects: interpolation method of 'sz3' algorithm for data reconstruction and the application of 'szx' algorithm on a 'Region of Interest(ROI)' - where a lesser data distortion is needed. We perform a through evaluation using NYX scientific dataset. Experiments show that compression ratio is improved by ~2x. Compression and decompression rates are improved by ~5-7x when contiguous ROI is preserved and only certain recursive levels of sx3 are processed.
Wednesday, 15 November 2023 3:57pm-4:06pm 505
Hide Details
Genome Assembly Using an Asynchronous Distributed Actor-Based Approach
DescriptionWe use genome assembly as a representative case to showcase the use of the ‘actor model’, a novel programming system for high-performance data-intensive workloads. The actor version of the 𝑘-mer counting kernel shows on average 1.6× speedup over similar MPI implementation. We provide a novel parallel algorithm that leverages the actor model to traverse de Bruijn graphs in a non-blocking, one-directional manner. Our findings highlight the potential of the actor model for writing simple and efficient parallel programs for data-heavy workloads.

Wednesday, 15 November 2023 4:06pm-4:15pm 505
Hide Details

File Aggregation for Asynchronous Multi-Level Checkpointing
DescriptionCheckpointing serves numerous functionalities in modern-day HPC systems and applications. In recent years, synchronous checkpointing, which blocks the application until checkpoints are persisted to external storage, suffers rising synchronization overheads at scale, resulting in little forward progress by the application. Therefore, asynchronous checkpointing has become more popular by quickly capturing checkpoints locally and flushing them in the background concurrently alongside the application. State-of-the-art solutions like VELOC utilize a file-per-process strategy, which is difficult for users and parallel file systems to manage. We implement a tunable N-to-M aggregation strategy within VELOC, obtaining 2.5x greater throughput than state-of-the-art aggregation library ADIOS2 and 1.5x higher throughput than the naive N-to-1 aggregation currently supported by VELOC.

Wednesday, 15 November 2023 4:15pm-4:24pm 505
Hide Details

Comparative Study of the Cache Utilization Trends for Regional Scientific Data Caches
DescriptionLarge scientific collaborations often have many users accessing the same data files, creating repeated file transfers over long distances. Data accesses to the distant data sources cause long latency to the applications and can be further delayed due to limited network bandwidth. XCache-based in-network regional data caching system stores scientific data and can reduce the network traffic and access latency. We examine the established Southern California Petabyte Scale Cache (So Cal Cache) and the newly deployed Chicago Regional Cache (Chicago Cache) for a high-energy physics experiment to analyze cache utilization trends and compare regional data access patterns. The results of the cache utilization trends show that the cache contributed to sharing a majority of data, and regional differences can be explained by the comparative study. Additionally, predictions of cache behavior show low error values in both regions, providing a useful tool for future resource planning.
Wednesday, 15 November 2023 4:24pm-4:33pm 505
Hide Details
Chasing Clouds with Donkeycar: Holistic Exploration of Edge and Cloud Inferencing Trade-Offs in E2E Self-Driving Cars
DescriptionIn autonomous driving, computational resources are strained by inference models. The viability of offloading inference to the cloud, considering latency between the car and data center, is questioned. We introduce a Cloud-Aided Real-time Inferencing Framework, integrating with Donkeycar and distributing computational load between cloud and edge. Utilizing Raspberry Pi 4 for edge inferencing and NVIDIA Triton Inference Server for the cloud, we demonstrate the framework's advantages, particularly in RNN performance, which achieved 90% autonomy. Our study includes a scaled car navigating obstacles, assessing factors like speed, resources, latency, and autonomy score. The system's performance shows faster inference time, eliminating bottlenecks, and processing 42 frames per second in the cloud, 11 times faster than on the edge. The poster will detail the strengths, limitations, and potential of leveraging cloud resources in real-time edge environments, focusing on autonomy scores and latency trade-offs.
Wednesday, 15 November 2023 4:33pm-4:42pm 505
Hide Details
Near-Optimal Reduce on the Cerebras Wafer-Scale Engine
DescriptionEfficient reduce and allreduce communication collectives are crucial building blocks in many workloads, including deep learning training, and have been optimized for various architectures. We provide the first systematic investigation of the reduce operation on the Cerebras Wafer-Scale Engine (WSE) using the Cerebras SDK. We improve upon existing reduce implementations by up to 5x in certain settings. We show that using at most three different implementations we can achieve performance at most 1.38x slower than an optimal reduction tree. Finally, we provide an allreduce that outperforms patterns like ring or butterfly by up to 2x.
We will (a) cover unique features of the Cerebras WSE, (b) introduce a model to accurately predict performance on the hardware, (c) discuss different reduce implementations, (d) analyze the results of running them using an accurate simulator and compare them against an optimal reduction tree, (e) show how to extend them to an efficient allreduce.
We will (a) cover unique features of the Cerebras WSE, (b) introduce a model to accurately predict performance on the hardware, (c) discuss different reduce implementations, (d) analyze the results of running them using an accurate simulator and compare them against an optimal reduction tree, (e) show how to extend them to an efficient allreduce.
Wednesday, 15 November 2023 4:42pm-4:51pm 505
Hide Details

Navigating the Molecular Maze: A Python-Powered Approach to Virtual Drug Screening
DescriptionThe COVID-19 pandemic has highlighted the power of using computational methods for virtual drug screening. However, the molecular search space is enormous and the common protein docking methods are still computationally intractable without access to the world’s largest supercomputers. Instead, researchers are using AI methods to provide a powerful new tool to help guide docking campaigns. In such approaches, a lightweight surrogate model is trained and then used to identify promising candidates for screening. We present ParslDock, a Python-based pipeline using the Parsl parallel programming library and the K-Nearest Neighbors machine learning model to screen a huge molecular space of molecules against arbitrary receptors. We achieved a 38X speedup with ParslDock compared to a brute-force docking approach.
Wednesday, 15 November 2023 4:51pm-5pm 505
Hide Details

Supercharging Scientific Serverless: Slashing Cold Starts with Python UniKernels
DescriptionServerless computing platforms use containers to create custom and isolated execution environments. Thus, the time to serve a function in the Function-as-a-Service (FaaS) paradigm, is dependent on the time to load the necessary container. FaaS platforms try to avoid "cold-starts'', instead pre-loading containers to serve workload. We focus on the problem of rapidly loading Python environments in the Globus Compute (previously funcX) platform. Globus Compute is unique in that it is deployed on HPC systems and thus suffers from costs of shared file systems. We evaluate containers and microvmms (Docker and Firecracker) and propose a new approach using lightweight Python Unikernels. We show considerable speed up in cold-start times using Unikernels.